
IBM introduced synthetic data generation aimed at transforming chatbots’ capabilities worldwide. Titled Large-scale Alignment for Chatbots (LAB), this method promises to address the longstanding challenges modern chatbots face.
Chatbots have garnered attention for their ability to emulate various personas, from pirates to accountants, yet their performance often falters with inaccuracies and digressions. This inconsistency stems from the limitations of their training data, primarily sourced from the Internet and supplemented with task-specific information.
Powered by large language models (LLMs), chatbots undergo pre-training on raw text to grasp the nuances of language. However, the quality of instruction data remains a significant hurdle, with human-generated data proving laborious and expensive, while synthetic data lacks diversity.
IBM’s LAB method offers a systematic approach to overcoming these obstacles. By generating synthetic data tailored to specific tasks and seamlessly integrating new knowledge into the foundational model, LAB promises to enhance chatbots’ capabilities significantly. This approach reduces the time and cost typically associated with training LLMs and ensures a more robust and versatile performance.
The introduction of LAB marks a pivotal moment in the evolution of chatbot technology, potentially reshaping how these virtual assistants interact with users across various domains. As businesses and industries increasingly rely on chatbots for customer service, information dissemination, and task automation, IBM’s innovative solution could herald a new era of efficiency and effectiveness in conversational AI.
“Instruction data is the lever for building a chatbot that behaves the way you want it to. Our method allows you to write a recipe for the problems you want your chatbot to solve and to generate instruction data to build that chatbot.”- AKASH SRIVASTAVA, chief architect of LLM alignment at IBM Research
What is Synthetic Data Generation?
Synthetic data generation is creating new data, either manually using tools like Excel or automatically through computer simulations or algorithms, to substitute for real-world data. This process involves generating fake data from an existing dataset or creating a completely new one if real data is unavailable. The generated data closely resembles the original data and can be produced in any size, at any time, and in any location.
Despite its artificial nature, synthetic data mathematically or statistically replicates real-world data, resembling data collected from actual objects, events, or people used for training AI models.
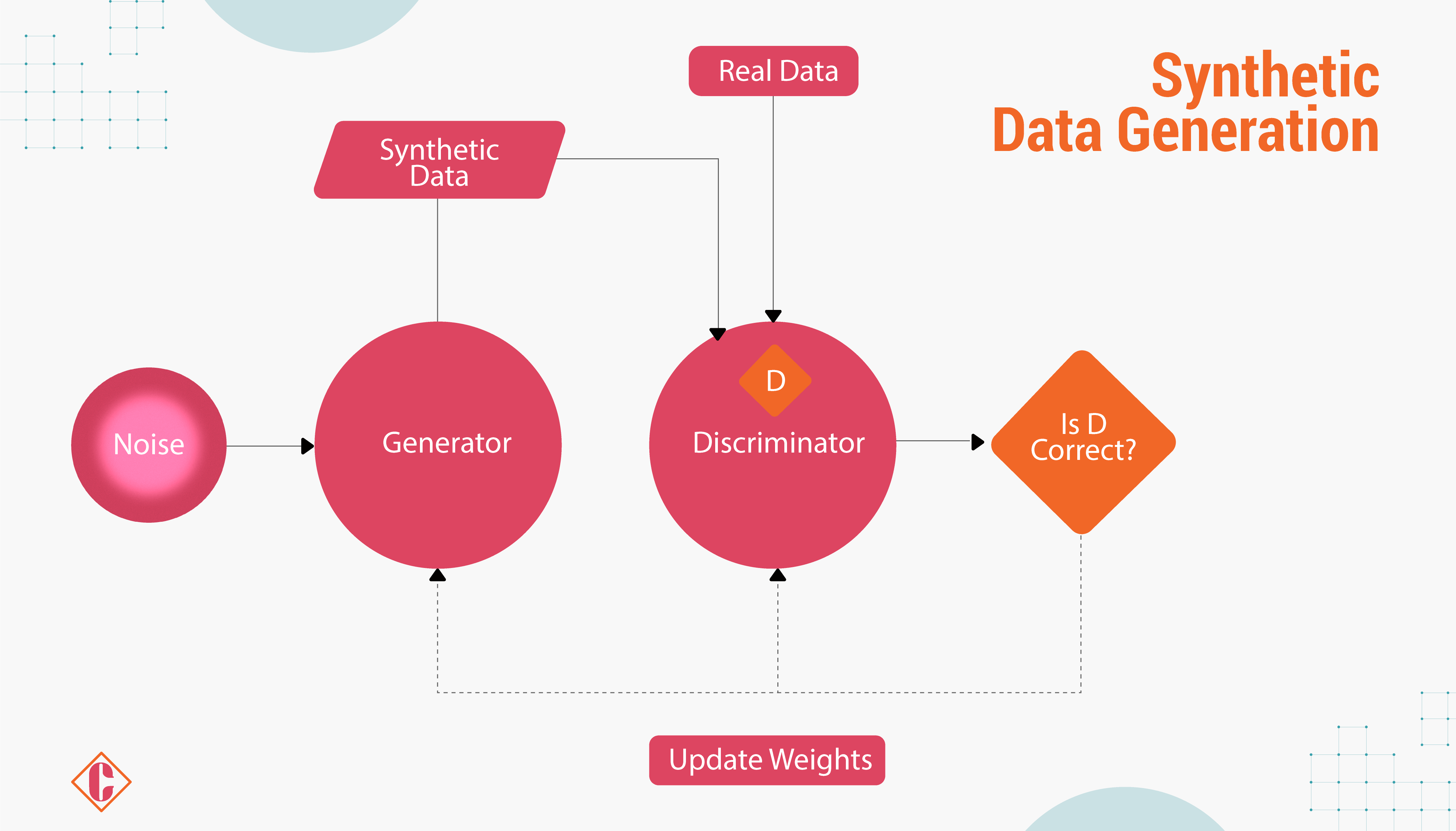 Advanced Methodology for Generating High-Quality Instruction Data
Advanced Methodology for Generating High-Quality Instruction Data
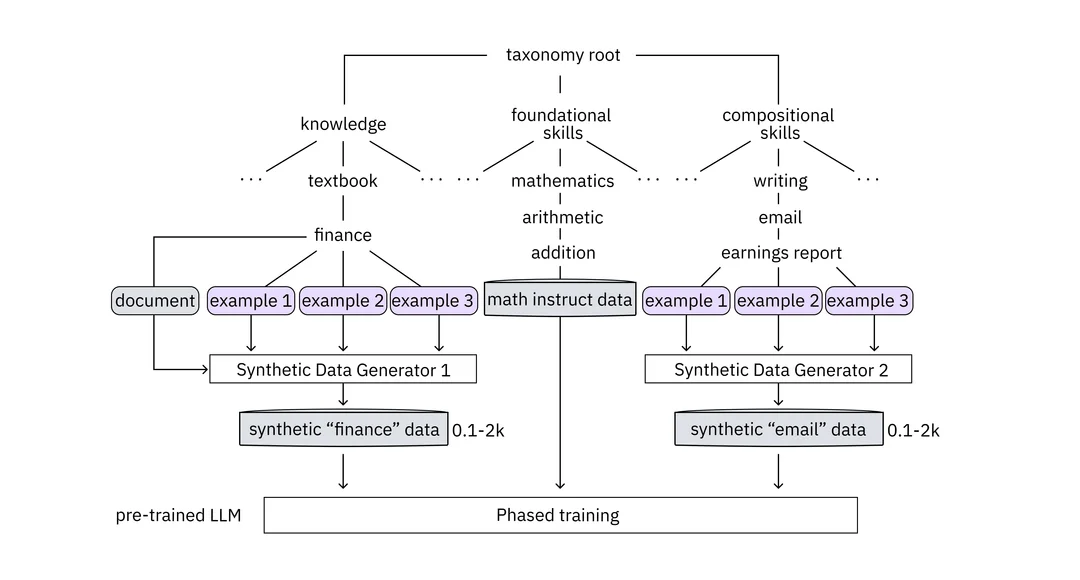
- IBM’s method for generating high-quality instruction data relies on a taxonomy that enables LLM developers to specify desired knowledge and skills for their chatbots.
- The taxonomy organizes the LLM’s existing knowledge and skills logically, aiding developers in identifying and filling gaps with new information and skills.
- A secondary LLM, the teacher model, formulates top-notch instructions in question-answer pairs tailored to the task.
- For example, training a chatbot to draft a CEO’s email summarizing third-quarter earnings would require comprehension of financial statements, basic mathematical abilities, and the ability to summarize financial data appropriately.
- IBM’s taxonomy divides instruction data into three main categories: knowledge, foundational skills, and compositional skills.
- The teacher model generates instructions for each category while maintaining quality control.
- In practice, the LLM developer uploads relevant financial documents and methods for calculating corporate earnings, allowing the teacher model to generate instructions grounded in this data.
- Additionally, the teacher model produces instructions for calculating earnings and composing the desired email based on provided sample earnings-report emails.
- The teacher model rigorously checks the quality of the generated data, discarding irrelevant questions and instructions containing inaccuracies.
- The vetted instructions are categorized into buckets for knowledge, foundational skills, and compositional skills, ready to be fed to the LLM in stages.
- This graduated training approach enables the LLM to progressively build upon its existing knowledge and skills, akin to human learning progression.
Impact of the LAB Method
IBM Research utilized the LAB method to generate a synthetic dataset of 1.2 million instructions. Two open-source LLMs, Labradorite 13B (based on Meta’s Llama-2-13B model) and Merlinite 7B (based on the Mistral 7B model), were trained on this dataset. The aligned models demonstrated competitiveness with state-of-the-art chatbots across various benchmarks, including coherent conversation and common-sense reasoning.
Two key features of LAB contribute to these impressive results.
- Firstly, the teacher model generates synthetic examples from each leaf node of the taxonomy, resulting in broader coverage of target tasks compared to random sampling methods.
- Secondly, LAB enables adding new knowledge and skills to the base LLM without integrating this information into the teacher model. According to David Cox, vice president for AI models at IBM Research, this eliminates the necessity for an all-powerful teacher model, distilling its capabilities into the base model.
LAB allows LLM developers to create instructions without concerns about the legality of using proprietary LLMs like GPT-4 for generating synthetic data. IBM’s LAB method emerged from the team’s realization that superior alignment data can enhance the capabilities of smaller, more cost-effective models tailored for enterprise requirements. While pre-training remains crucial, providing the model with highly curated task-specific instructions holds equal importance.
FAQs
1. What is Synthetic Data?
Synthetic data refers to artificially manufactured information distinct from data originating from real-world occurrences. It is algorithmically generated and substitutes test data sets derived from production or operational data. Synthetic data is utilized to validate mathematical models and train machine learning (ML) models.
Acquiring high-quality, real-world data is challenging, expensive, and time-consuming. However, synthetic data technology allows users to swiftly, conveniently, and digitally generate data tailored to their specific requirements in any desired quantity.
2. Why is Synthetic Data important?
Synthetic data is increasingly embraced due to its numerous advantages over real-world data. According to Gartner’s prediction, by 2024, 60% of the data utilized for developing AI and analytics will be artificially produced.
The primary application of synthetic data lies in training neural networks and ML models. Developers require meticulously labeled datasets, ranging from a few thousand to tens of millions of items. Synthetic data can mimic real datasets, allowing companies to generate diverse and extensive training data without substantial time and financial investment.
3. How does the Methodology for Generating High-Quality Instruction Data Work?
The methodology relies on a taxonomy that organizes existing knowledge and skills logically. A secondary LLM, the teacher model, formulates instructions tailored to the task. These instructions are categorized into knowledge, foundational, and compositional skills, maintaining quality control throughout the process.
4. What are the Key Features of the LAB Method?
The LAB method enables the generation of synthetic data from each leaf node of the taxonomy, providing broader coverage of target tasks. Additionally, it allows the addition of new knowledge and skills to the base LLM without integrating this information into the teacher model, enhancing flexibility and efficiency.
5. How does the LAB Method Impact Chatbot Performance?
Utilizing the LAB method, researchers generated a synthetic dataset and trained open-source LLMs, resulting in competitive performance across various benchmarks. This method enhances chatbot capabilities significantly, offering a cost-effective and efficient solution for training and improving chatbot performance.
6. What are the Advantages of the LAB Method for Chatbot Development?
The LAB method provides a systematic approach to overcoming the challenges of modern chatbots. It reduces the time and cost associated with training LLMs, ensures a more robust performance, and allows for adding new knowledge and skills without constraints, thereby reshaping the landscape of conversational AI.
[To share your insights with us as part of editorial or sponsored content, please write to sghosh@martechseries.com]