
On July 19, 2024, CrowdStrike, a prominent cybersecurity company, experienced a significant global IT outage that disrupted services for many of its clients. This incident underscores the vulnerabilities of heavy reliance on SaaS (Software as a Service) offerings and public cloud infrastructures.
CrowdStrike, established in 2011, is renowned for its next-generation endpoint protection, threat intelligence, and incident response services. The unexpected outage severely impacted the company’s ability to deliver critical security functions, causing substantial disruptions for organizations worldwide. The outage not only highlighted the risks of cyber reliance but also the need for robust contingency planning.
CrowdStrike’s immediate response involved intensive technical troubleshooting to restore services. Customers reported encountering BSOD (Blue Screen of Death) errors, exacerbating the impact. Although the incident raised serious concerns about the resilience and reliability of cybersecurity infrastructures, the company’s prompt action and communication were pivotal in mitigating the fallout.
This event serves as a potent reminder of the words of cybersecurity expert Bruce Schneier: “Security is a process, not a product.” It emphasizes the continuous effort required to safeguard digital environments against unforeseen disruptions.
Also Read: Advanced Endpoint Protection Strategies for 2024
The Outage: What Happened?
The CrowdStrike outage began late Thursday night and extended into Friday, disrupting various critical services. On the night of July 18, several states, including Alaska and Arizona, experienced 911 service outages, while some hospitals faced technology issues. By 2-3 a.m. on July 19, the Federal Aviation Administration grounded flights for Delta, American, United, and Allegiant Airlines. Spirit Airlines also reported issues with its reservation system.
Between 5-6 a.m., public transit systems in the Northeast, including Washington, DC, faced delays, though New York City’s transportation services remained largely unaffected. CrowdStrike issued an advisory at 5:30 a.m., acknowledging crashes of its software on Microsoft Windows operating systems.
From 6-7 a.m., the White House began investigating the incident, with global banks reporting disruptions. Portland’s emergency services manually handled calls due to system issues. United Airlines resumed some flights by 8-9 a.m., but other airports faced continued disruptions. By late morning, several healthcare systems, including Mass General Brigham and Penn Medicine, reported service delays or cancellations.
As of Saturday morning, Microsoft estimated the outage affected 8.5 million Windows devices. The residual impact caused significant flight delays, with at least 3,375 flights delayed and 1,200 canceled across the U.S., with Hartsfield-Jackson International Airport being the most affected.
Also Read: Advanced Threat Detection with Managed Security Service Providers
Microsoft’s Response to the CrowdStrike Outage
Since the onset of the CrowdStrike outage, Microsoft has prioritized communication and collaboration with affected parties, including customers, CrowdStrike, and external developers, to gather information and expedite solutions. The company acknowledges the disruption this incident has caused for businesses and individuals alike. Microsoft’s response has been focused on providing technical guidance and support to facilitate the safe restoration of disrupted systems. The key actions taken include:
- Collaboration with CrowdStrike: Microsoft has worked closely with CrowdStrike to automate their efforts in developing a solution. CrowdStrike has provided a workaround to address the issue and issued a public statement. Additionally, instructions for remedying the situation on Windows endpoints have been posted on the Windows Message Center.
- Deployment of Engineering Resources: Microsoft has mobilized hundreds of engineers and experts to work directly with customers to restore services. This hands-on approach has been crucial in addressing and mitigating the impact of the outage.
- Coordination with Cloud Providers: The company has engaged with other cloud providers, including Google Cloud Platform (GCP) and Amazon Web Services (AWS), to share insights on the industry-wide impact and to coordinate ongoing discussions with CrowdStrike and customers.
- Provision of Remediation Documentation: Swiftly published manual remediation documentation and scripts to assist customers in addressing the issue. These resources are available through the designated support channels.
- Status Updates: Microsoft has kept customers informed with real-time updates on the incident through the Azure Status Dashboard.
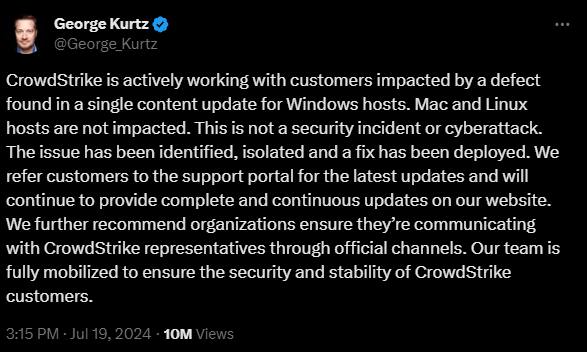
Official Statement from CrowdStrike:
Impact Assessment
The global IT outage involving CrowdStrike has underscored the vulnerabilities inherent in interconnected supply chains. This disruption impacted approximately 674,620 direct customer relationships between CrowdStrike and Microsoft, with over 49 million individuals affected indirectly, as reported by Interos. The United States, accounting for 41% of the affected entities, experienced the most significant impact, but Europe and Asia also reported notable disruptions. Major ports, including those in New York, Los Angeles, and Rotterdam, faced temporary shutdowns, while air freight hubs encountered extensive delays due to grounded flights.
- Supply Chain Disruptions The outage has exacerbated existing supply chain challenges amidst rising global demand and freight prices. The disruption has caused ripple effects across international trade, impacting various sectors. Interos data reveals that CrowdStrike and Microsoft’s systems disruptions affected an estimated 674,620 direct customer relationships. When considering secondary and tertiary impacts, the number of affected relationships extends to over 49 million.
- Port and Air Freight Impacts Ports from New York to Los Angeles and Rotterdam reported temporary shutdowns, with Rotterdam handling approximately 1.3 million tons of cargo daily. UK ports and other European ports also experienced significant IT issues. Air freight, heavily reliant on global hubs, was particularly hard hit, with thousands of flights grounded or delayed. This has led to delays in goods movement, impacting sectors reliant on timely deliveries, such as the semiconductor supply chain.
- Regional Impact The U.S. saw substantial disruptions, with 41% of affected entities located in the country. European nations, including the UK, Germany, and France, also faced significant impacts, highlighting the global nature of the outage. In the U.S., the outage has increased cyber risks due to disrupted security protocols, leading to potential vulnerabilities and heightened risk of cyberattacks.
- Sector-Wide Effects The outage has influenced a broad range of industries. Airlines and banks have been significantly affected, but disruptions also extend to professional services, wholesale, and manufacturing industries. The impact has led to delays in critical infrastructure and services, affecting businesses and consumers globally.
- Government and Municipal Impact CrowdStrike’s extensive use by U.S. state governments and major cities underscores the potentially severe consequences of cybersecurity. A prolonged outage could compromise municipal cybersecurity defenses, impacting essential services such as public safety, transportation, and healthcare
Key Takeaways and Recommendations for IT and Security Professionals for Future Outages
The recent CrowdStrike outage has underscored the importance of robust IT management strategies. To bolster resilience and mitigate the risk of future disruptions, CIOs should consider the following key strategies:
1. Thorough Update Management
Implementing a thorough update management strategy is crucial. CIOs should ensure extensive pre-deployment testing across various environments and configurations to identify potential issues early. Utilize staging environments that closely mirror production setups for comprehensive testing. This should encompass automated, manual, and regression testing to confirm that new updates do not disrupt existing functionalities.
2. Phased Deployment Approach
Mitigate risks by adopting a phased deployment strategy. Start by rolling out updates to a small, controlled group before a full-scale implementation. This approach allows for monitoring and addressing issues early. Establish robust rollback procedures to quickly revert to a stable version if problems arise. Automated rollback capabilities can further streamline this process, enabling quicker recovery with minimal manual intervention.
3. Enhanced Monitoring and Incident Response
Utilize advanced monitoring tools to detect anomalies immediately after deployment. Implement real-time monitoring and alerting systems to address issues as they arise. Develop comprehensive incident response plans with clear protocols for rapid identification, isolation, and resolution of issues. Include root cause analysis and post-incident reviews to refine response strategies continuously.
4. Avoid Single Points of Failure
Increase resilience by diversifying solutions and implementing redundancy and failover mechanisms. Ensure critical systems remain operational even if one component fails. Consider adopting hybrid or multi-cloud infrastructures to distribute workloads across multiple environments, enhancing redundancy and disaster recovery capabilities. Load balancing and geographic distribution of resources can further reduce risks associated with localized failures.
5. Regular Infrastructure and Disaster Recovery Assessment
Continuously evaluate infrastructure resilience and disaster recovery plans. Regularly test disaster recovery strategies through simulated drills to identify weaknesses and areas for improvement. Collaborate with reliable providers to enhance preparedness and response capabilities by leveraging their expertise and resources.
These strategies, while well-established, are reinforced by incidents like the CrowdStrike outage. By adhering to these best practices, CIOs can build a more resilient IT infrastructure capable of enduring unforeseen challenges.
Final Words
In conclusion, the CrowdStrike outage underscores the inherent vulnerabilities of heavy reliance on SaaS offerings and public cloud infrastructures. The significant disruption caused to critical services globally highlights the urgent need for robust contingency planning and resilient IT management strategies. This incident is a stark reminder of the continuous effort required to safeguard digital environments against unforeseen disruptions.
The broader implications for the cybersecurity industry are profound, emphasizing the necessity for update management, phased deployment approaches, enhanced monitoring, and the avoidance of single points of failure. Businesses must adopt these strategies to build more secure and robust infrastructures capable of enduring future challenges. By learning from such incidents and implementing best practices, organizations can better prepare for and mitigate the impact of similar events in the future.
[To share your insights with us as part of editorial or sponsored content, please write to psen@itechseries.com]