
NVIDIA has announced growth in the Phi-3 Mini open language model by Microsoft. Nvidia accelerates the open language model with its TensorRT-LLM. It is an open-source library for improving large language model inference. This is possible when the model inference runs from PC to cloud on NVIDIA GPUs.
Understanding Phi-3 Mini: A Lightweight Solution for Simpler Tasks
Phi-3 Mini is devised to solve simpler tasks and service businesses working under resource constraints. Such strategic focus has encapsulated Microsoft’s commitment to democratizing AI by letting small businesses enjoy the fruits of advanced technologies with a definite bang.
The models’ accessibility has been improved through availability on multiple platforms: Azure AI model catalog on Microsoft, Hugging Face Machine Learning Model Platform, and Ollama Framework for local machine model deployment. Model optimization has been done for NVIDIA GPUs, and it is very easy to integrate NVIDIA’s software tool, NVIDIA Inference Microservices (NIM), making the model’s performance at par across different environments.
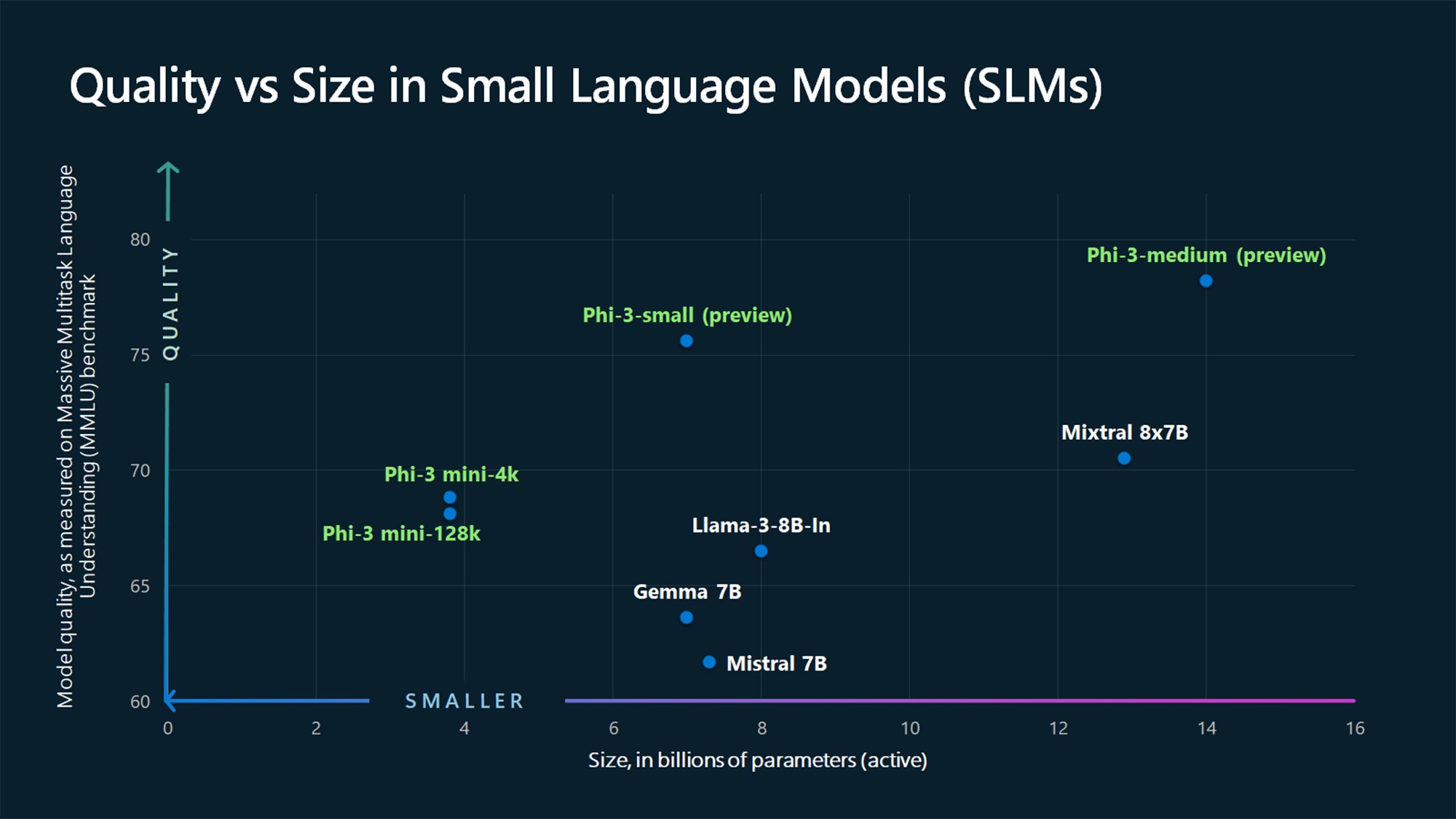 Trained on a dataset of 3.8 billion parameters, Phi-3 Mini knows how to handle simpler tasks and is yet affordable and accessible for businesses that have limited resources. Unlike larger language models, GPT-4, its parameters are relatively smaller; it’s trained specifically for simpler tasks and marks a part of Microsoft’s mission to introduce SLMs for specific kinds of simpler tasks. Not only does it lower costs, but it also streamlines the speed at which operations are done, especially at the edge, and expands the scope of use cases enterprises and consumers have for Generative AI.
Trained on a dataset of 3.8 billion parameters, Phi-3 Mini knows how to handle simpler tasks and is yet affordable and accessible for businesses that have limited resources. Unlike larger language models, GPT-4, its parameters are relatively smaller; it’s trained specifically for simpler tasks and marks a part of Microsoft’s mission to introduce SLMs for specific kinds of simpler tasks. Not only does it lower costs, but it also streamlines the speed at which operations are done, especially at the edge, and expands the scope of use cases enterprises and consumers have for Generative AI.
Also Read: Meta’s Llama 3 Open Models Now Available on IBM Watsonx
Advancements and Variants of Phi-3 Mini
Phi-3 Mini is a technological leap ahead of all language model technology. Its capabilities are at least ten times ahead of those of its predecessors. Where Phi-2 was a research-grade product, today, Phi-3 Mini is licensed for research and broad commercial use, opening its applicability to a wider field.
Making training at such an impressive dataset possible in just seven days, Phi-3 Mini managed this feat by training with 512 NVIDIA H100 Tensor Core GPUs. The training was completed on an immense dataset comprising 3.3 trillion tokens.
Phi-3 Mini has two variants, optimized for different token sizes and tailored for different applications. One variant allows for 4k tokens, while the other is unparalleled in scope: it was developed to cater to very long contexts at 128K tokens. It is the first model of its type to be capable of answering questions with 128,000 tokens in context while providing answers that will be all the more contextually rich.
Users can easily access Phi-3 Mini from ai.nvidia.com. Available as an NVIDIA NIM (NVIDIA Inference Microservice), Phi-3 Mini has a standard application programming interface. The ease of deployment allows for very easy deployment across various platforms and environments.
Improving Efficiency for Edge Computing
With Phi-3, developers engaged in autonomous robotics and embedded systems can leverage community-driven tutorials, such as those available on Jetson AI Lab. This will help them master the creation and deployment of generative AI. In addition, the deployment of Phi-3 on NVIDIA Jetson further facilitates their engagements.
With a modest parameter count of 3.8 billion, Phi-3 Mini runs efficiently on edge devices. These parameters, akin to finely-tuned knobs within memory, ensure the model’s responsiveness to input prompts with exceptional accuracy.
Phi-3 is a valuable asset for scenarios constrained by cost and resources, particularly for simpler tasks. Despite its compact size, the model surpasses larger counterparts on critical language benchmarks while meeting stringent latency requirements.
What TensorRT-LLM Integration Brings?
TensorRT-LLM integrates with Phi-3 Mini’s extended context window, leveraging optimizations and kernels such as LongRoPE, FP8, and inflight batching. These enhancements significantly improve inference throughput and reduce latency. The TensorRT-LLM implementations will soon be accessible in the examples folder on GitHub, enabling developers to convert effortlessly to the optimized TensorRT-LLM checkpoint format. Subsequently, these models can be seamlessly deployed using the NVIDIA Triton Inference Server.
NVIDIA’s Commitment to Open Systems
NVIDIA is a prominent contributor to the open-source ecosystem, having released more than 500 projects under open-source licenses. The company actively participates in various external initiatives, including, but not limited to, JAX, Kubernetes, OpenUSD, PyTorch, and the Linux kernel. By engaging in these endeavors, NVIDIA demonstrates its steadfast support for various open-source foundations and standards bodies.
Today’s announcement builds upon NVIDIA’s longstanding collaborations with Microsoft, marking yet another milestone in their joint efforts to drive innovation across multiple domains. These collaborations have yielded significant advancements, including the acceleration of DirectML, enhancements to Azure cloud services, groundbreaking research in generative AI, and transformative initiatives in healthcare and life sciences.
FAQs
1. What is Phi-3 Mini, and how does it differ from previous models?
Phi-3 Mini is a revolutionary language model developed by NVIDIA, featuring a capacity of 3.8 billion parameters. Unlike its predecessors, Phi-3 Mini is specifically tailored for handling simpler tasks, making it accessible and cost-effective for businesses with limited resources.
2. How does Phi-3 Mini contribute to the democratization of AI?
Phi-3 Mini aligns with Microsoft’s commitment to democratizing AI by offering practical solutions for companies of all sizes. Its lightweight design and optimized performance enable businesses with constrained resources to leverage advanced AI technologies effectively.
3. Where can Phi-3 Mini be deployed, and what platforms support it?
Phi-3 Mini is available on various platforms, including Microsoft’s Azure AI model catalog, Hugging Face’s machine learning model platform, and Ollama, a framework for local machine model deployment. Additionally, it is optimized for NVIDIA’s GPUs and integrated with NVIDIA’s software tool, NVIDIA Inference Microservices (NIM), for enhanced accessibility and performance.
4. What are the advantages of using Phi-3 Mini for businesses?
Phi-3 Mini offers several advantages for businesses, including cost-effectiveness, accessibility, and improved operational speed, particularly at the edge. Its ability to handle simpler tasks efficiently makes it suitable for a wide range of enterprise and consumer use cases in Generative AI.
5. How does Phi-3 Mini contribute to the broader landscape of language models and AI research?
Phi-3 Mini represents a significant advancement in language model technology, showcasing the potential for developing models tailored for specific tasks and resource constraints. Its release underscores ongoing efforts to explore new avenues for AI research and development, particularly in making advanced AI technologies more accessible and practical for real-world applications.
[To share your insights with us as part of editorial or sponsored content, please write to sghosh@martechseries.com]