
The advancements in generative AI models have opened new doors for solving complex problems across industries. However, these larger models with billions or even trillions of parameters come with increased training, tuning, and inference demands. Managing these efficiently requires a cohesive AI stack integrating optimized computing, storage, networking, software, and development frameworks.

To meet these challenges, Google is introducing Cloud TPU v5p, their most powerful and scalable AI accelerator yet. TPUs have been instrumental in training and serving AI-powered products like YouTube, Gmail, Google Maps, Google Play, and Android. Gemini, their latest and most versatile AI model, was trained and runs on TPUs.
Google Cloud is unveiling the AI Hypercomputer, a revolutionary supercomputer architecture. This hypercomputer employs an integrated system of optimized hardware, open software, leading ML frameworks, and flexible consumption models. Unlike traditional methods that enhance AI workloads piecemeal, the AI Hypercomputer employs systems-level codesign to enhance efficiency and productivity across AI training, tuning, and serving, reducing bottlenecks and inefficiencies.
Cloud TPU v5p: Unveiling Unprecedented Power and Scalability
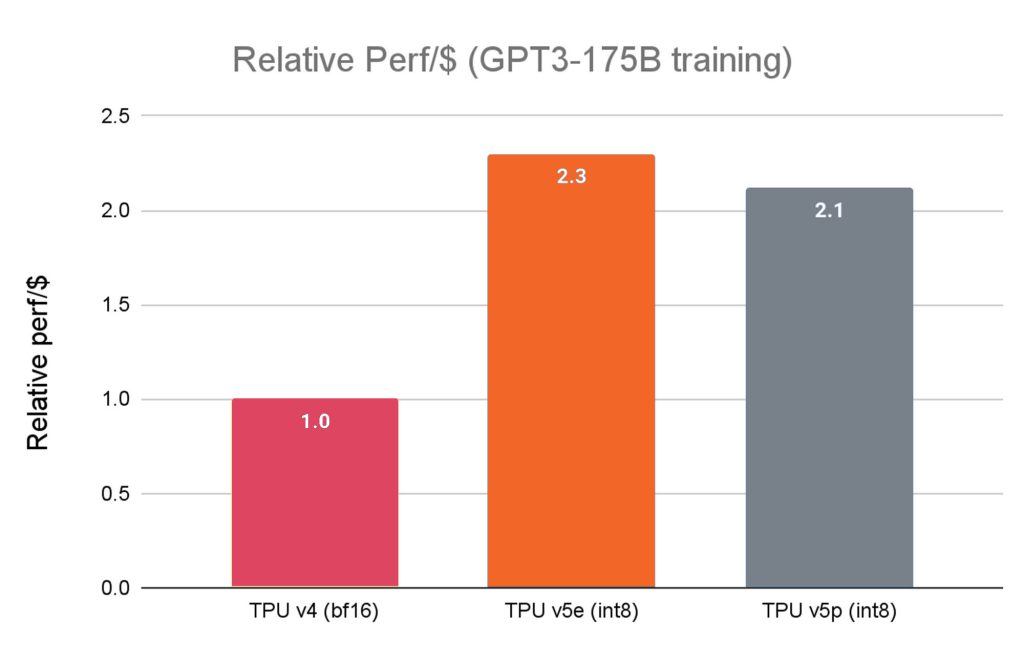
Within the landscape of TPU accelerators, the Cloud TPU v5p emerges as a testament to heightened power and scalability. Preceded by the Cloud TPU v5e’s market debut earlier this year, which showcased a notable 2.3X enhancement in price performance compared to its precursor, the v41 TPU, the v5p stands as our most robust TPU offering to date.
 A TPU v5p pod integrates an impressive ensemble of 8,960 chips, interlinked via the highest-bandwidth inter-chip interconnect (ICI) operating at 4,800 Gbps/chip, utilizing a 3D torus topology. Comparatively, in contrast to its predecessor, TPU v4, the TPU v5p excels with more than a twofold increase in Floating Point Operations per Second (FLOPS) and a threefold augmentation in high-bandwidth memory (HBM).
A TPU v5p pod integrates an impressive ensemble of 8,960 chips, interlinked via the highest-bandwidth inter-chip interconnect (ICI) operating at 4,800 Gbps/chip, utilizing a 3D torus topology. Comparatively, in contrast to its predecessor, TPU v4, the TPU v5p excels with more than a twofold increase in Floating Point Operations per Second (FLOPS) and a threefold augmentation in high-bandwidth memory (HBM).
Engineered to deliver unparalleled performance, adaptability, and scalability, the TPU v5p demonstrates the capability to train large LLM models with a remarkable 2.8X speed boost over the preceding TPU v4. Additionally, incorporating second-generation SparseCores empowers the TPU v5p to accelerate the training of embedding-dense models by 1.9X compared to the TPU v42.
Beyond performance enhancements, the TPU v5p showcases a significant leap in scalability, surpassing the TPU v4 by a staggering 4X in total available FLOPs per pod. The augmentation in the number of chips per pod and the floating-point operations per second (FLOPS) yields substantial advancements in training speed and relative performance, affirming the TPU v5p’s prowess in high-performance computing.
 Google AI Hypercomputer: Maximizing Performance and Efficiency at Scale
Google AI Hypercomputer: Maximizing Performance and Efficiency at Scale
 Google AI Hypercomputer: Maximizing Performance and Efficiency at Scale
Google AI Hypercomputer: Maximizing Performance and Efficiency at ScaleAchieving both scale and speed is a requisite but not an endpoint to meet the evolving demands of modern AI/ML applications and services. Fusing hardware and software components is pivotal, necessitating an integrated, secure, and reliable computing system. Drawing from decades of research and development, Google presents the AI Hypercomputer, a culmination of technologies meticulously optimized to harmonize with contemporary AI workloads.
Performance-Optimized Hardware
AI Hypercomputer embodies performance-centric computing, storage, and networking components. Anchored in an ultra-scale data center infrastructure, it leverages high-density architecture, liquid cooling mechanisms, and our proprietary Jupiter data center network technology. These advancements are rooted in efficiency-driven technologies, embracing clean energy sources and an unwavering commitment to water stewardship, aligning with our trajectory towards a carbon-neutral future.
Open Software
Developers harness the potential of our performance-optimized hardware via open software tools tailored to fine-tune, manage, and dynamically orchestrate AI training and inference workloads. Seamless access to prevalent ML frameworks like JAX, TensorFlow, and PyTorch is inherent. Both JAX and PyTorch are empowered by the OpenXLA compiler, enabling the construction of intricate LLMs. XLA, as a foundational element, facilitates the development of complex multi-layered models across diverse hardware platforms, ensuring efficient model creation for varied AI use cases.
Specialized Software Solutions
Unique Multislice Training and Multihost Inferencing software streamline scaling, training, and serving workloads across the AI landscape. Developers can seamlessly scale to tens of thousands of chips to support demanding AI tasks.
Deep Integration with Google Services
Deeply integrated with Google Kubernetes Engine (GKE) and Google Compute Engine, AI Hypercomputer ensures efficient resource management, consistent operational environments, autoscaling capabilities, node-pool auto-provisioning, auto-checkpointing, auto-resumption, and swift failure recovery.
Flexible Consumption Models
AI Hypercomputer offers a gamut of dynamic consumption choices. In addition to conventional options like Committed Use Discounts (CUD), on-demand, and spot pricing, it introduces tailored consumption models via the Dynamic Workload Scheduler. The Scheduler introduces the Flex Start mode for enhanced resource accessibility and optimized economics, alongside the Calendar mode, tailored for predictability in job-start times for specific workloads.
Powering AI’s Future with Google’s Expertise
Salesforce’s Enhanced Training Efficiency
“Utilizing Google Cloud’s TPU v5p for pre-training Salesforce’s foundational models, we’ve observed significant speed enhancements. The transition from Cloud TPU v4 to v5p using JAX was seamless, showcasing up to a 2X performance boost. Leveraging the Accurate Quantized Training (AQT) library’s native support for INT8 precision format, we’re excited to optimize our models further.” – Erik Nijkamp, Senior Research Scientist, Salesforce.
Lightricks’ Accelerated Training Cycles
“The remarkable performance and expansive memory capacity of Google Cloud TPU v5p enabled us to train our text-to-video model without dividing it into separate processes. This efficient hardware utilization accelerated each training cycle, facilitating swift experimentation. Rapid model iteration is a pivotal advantage in our competitive field of generative AI.” – Yoav HaCohen, Ph.D., Core Generative AI Research Team Lead, Lightricks.
Google DeepMind and Google Research Advancements
“In our preliminary usage, we’ve witnessed a 2X speedup in LLM training workloads using TPU v5p chips compared to our TPU v4 generation. Enhanced support for ML frameworks and orchestration tools on v5p allows us to scale more efficiently. The second generation of SparseCores significantly improves performance for embeddings-heavy workloads, vital in our extensive research on cutting-edge models like Gemini.” – Jeff Dean, Chief Scientist, Google DeepMind and Google Research.
Google’s Commitment to Empower AI Innovation
Google is dedicated to harnessing AI’s potential to tackle intricate problems. Until recently, training and scaling large foundation models were complex and costly for many. Now, with Cloud TPU v5p and AI Hypercomputer, we share decades of AI and systems design research with our customers, empowering faster, more efficient, and cost-effective AI innovation.
[To share your insights with us, please write to sghosh@martechseries.com]