
Stability.ai, a company building open AI tools, has announced the launch of Stable LM Zephyr 3B, marking a significant advancement in its series of lightweight LLMs. Explicitly designed for instruction following and Q&A tasks, this new chat model, an extension of the renowned Stable LM 3B-4e1t, draws inspiration from HuggingFace’s Zephyr 7B model. Boasting 3 billion parameters, Stable LM Zephyr empowers edge devices with unparalleled efficiency in generating text, catering seamlessly to diverse text generation requirements, from basic queries to intricate instructional contexts.

Insights into Stable LM Zephyr 3B Training
The development process behind Stable LM Zephyr 3B centered on crafting a high-performing text generation model attuned to human preferences. Drawing inspiration from the Zephyr 7B model, the training pipeline was adapted. Supervised fine-tuning occurred across various instruction datasets, including UltraChat, MetaMathQA, Evol Wizard Dataset, and Capybara Dataset. Subsequently, the model underwent alignment with the Direct Preference Optimization (DPO) algorithm, utilizing the UltraFeedback dataset sourced from the OpenBMB research group. This dataset comprises 64,000 prompts paired with corresponding model responses. Noteworthy models like Zephyr-7B, Neural-Chat-7B, and Tulu-2-DPO-70B have recently employed the Direct Preference Optimization (DPO) method successfully. However, Stable Zephyr distinguishes itself as one of the pioneering models in this category, boasting an efficient parameter size of 3B.
MT-Bench: A Novel Benchmark for Assessing Large Language Models
Researchers at the University of California, Berkeley, have developed a novel benchmark for evaluating large language models (LLMs) called MT-Bench. This comprehensive benchmark assesses a variety of tasks, including writing, coding, reasoning, and role-playing, providing valuable insights into the capabilities and limitations of different LLM architectures.
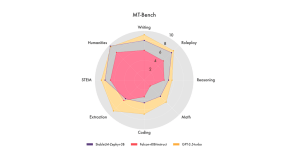 MT-Bench was evaluated on several prominent LLMs, including GPT-3.5-turbo, StableLM-Zephyr-38, and Falcon-40B-Instruct. While GPT-3.5-turbo emerged as the overall leader on the benchmark, each LLM demonstrated unique strengths and weaknesses. Notably, GPT-3.5-turbo excelled in writing and coding tasks, while StableLM-Zephyr-38 displayed superior performance in reasoning and role-playing scenarios.
MT-Bench was evaluated on several prominent LLMs, including GPT-3.5-turbo, StableLM-Zephyr-38, and Falcon-40B-Instruct. While GPT-3.5-turbo emerged as the overall leader on the benchmark, each LLM demonstrated unique strengths and weaknesses. Notably, GPT-3.5-turbo excelled in writing and coding tasks, while StableLM-Zephyr-38 displayed superior performance in reasoning and role-playing scenarios.
The results of this evaluation underscore the significant progress made in the field of LLM development in recent years. All of the tested LLMs exhibited substantial improvements compared to earlier models, showcasing the potential for LLMs to revolutionize various industries and applications.
MT-Bench is a valuable tool for researchers and developers in the LLM domain. It enables the objective assessment of LLM performance across diverse tasks, guiding further advancements in LLM technology and facilitating the identification of areas for improvement. 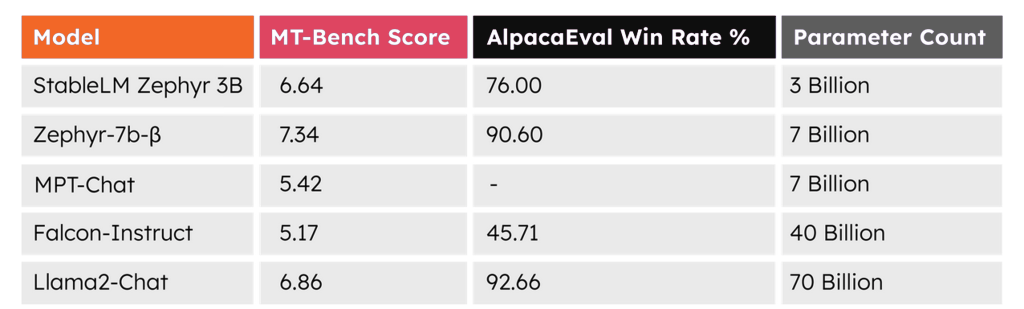
Additionally, MT-Bench empowers businesses and organizations to leverage the capabilities of LLMs strategically, driving efficiency and productivity across various domains.
Facilitating Diverse Applications
Stable LM Zephyr 3B is an elegant yet precise model proficient in managing a spectrum of linguistic tasks with exceptional efficiency and accuracy. Engineered to excel in instructional and Q&A tasks, its adaptability extends across many intricate applications. From the nuanced realms of copywriting and summarization to the realms of instructional design and content personalization, this model showcases its versatility. Additionally, it furnishes robust, insightful analyses rooted in the input data. Remarkably, these capabilities are delivered while maintaining its lean parameter size 3 billion, rendering it 60% smaller than 7B models. This efficiency facilitates utilization on devices that lack the computational prowess of dedicated high-end systems.
FAQs
1. What is MT-Bench, and how does it contribute to evaluating large language models (LLMs)?
MT-Bench is a benchmark developed by researchers at the University of California, Berkeley, specifically designed to assess the capabilities and limitations of different LLM architectures. It evaluates a range of tasks, such as writing, coding, reasoning, and role-playing, offering insights into LLM performance.
2. How was the performance of Stable LM Zephyr 3B assessed on the MT-Bench benchmark?
Stable LM Zephyr 3B was evaluated alongside other prominent LLMs like GPT-3.5-turbo and Falcon-40B-Instruct on the MT-Bench benchmark. While GPT-3.5-turbo emerged as the overall leader, Stable LM Zephyr 3B displayed superior performance in reasoning and role-playing tasks, showcasing unique strengths compared to other models.
3. What are the potential applications of Stable LM Zephyr 3B in diverse industries?
Stable LM Zephyr 3B is versatile and capable of handling tasks ranging from copywriting and summarization to instructional design and content personalization. Its efficient 3 billion parameter size makes it suitable for deployment on devices lacking high computational power, broadening its applications across various industries and domains.
[To share your insights with us, please write to sghosh@martechseries.com]