
In the age of accelerated digital transformation, businesses strive for increased productivity and unparalleled consumer experiences. This transition speeds up interactions, transactions, and decision-making and generates vast volumes of data, unveiling novel insights into operations, clientele, and market dynamics. Leveraging machine learning becomes pivotal in harnessing this data deluge to gain a competitive edge. ML models adeptly discern patterns within colossal datasets, empowering swift, precise decision-making on a scale surpassing human capabilities. This agility enables both humans and applications to take prompt and informed actions.

However, amidst this data-driven evolution, businesses realize that creating a machine learning model marks just one phase in the comprehensive ML lifecycle. The ML lifecycle encompasses three pivotal stages: data and feature engineering, model development, and model production. Initially, data science teams often embark on a self-built approach. Still, as they expand, they pivot towards standardizing their lifecycle on an ML platform or, more recently, a cloud data platform. Leveraging libraries, notebooks, and the broader ML ecosystem is instrumental throughout this journey.
Challenges in the Machine Learning Lifecycle
Building and deploying machine learning models presents formidable challenges. Ensuring the reproducibility and accessibility of pipelines and results for data scientists, engineers, or stakeholders can be equally daunting. Frequently, the lack of proper documentation or the complexity of replication forces the abandonment of prior work.
While the initial development of models demands significant attention, long-term management often gets overlooked. What does this encompass? It involves comparing versions of ML models and associated artifacts—code, dependencies, visualizations, intermediate data, and more. This tracking facilitates understanding what models are operational, their locations, and the redeployment or rollback of updated models when necessary. Each facet demands distinct tools, rendering the management of the ML lifecycle notably more challenging than the conventional software development lifecycle (SDLC).
This paradigm shift introduces considerable challenges, distinct from traditional software development lifecycles, including:
1. Diverse ML Toolsets
The lack of standardization across libraries and frameworks compounds the multitude and diversity of tools used in ML.
2. Insufficient Tracking and Management
The continuous nature of ML development and a shortage of adequate tools for tracking and managing machine learning models and experiments.
3. Complex productionization
The intricacies in transitioning ML models to production are due to the lack of integration among data pipelines, ML environments, and production services.
Databricks’ Managed MLflow: Elevating ML Lifecycle Operations
Managed MLflow, an extension of the open-source MLflow platform developed by Databricks, accentuates the focus on enterprise-grade reliability, security, and scalability within machine learning lifecycle management. This augmentation includes the incorporation of cutting-edge LLMOps features in the latest MLflow update, enriching its capacity to oversee and deploy large language models (LLMs).
The recent advancements in MLflow introduce an expanded LLM support system facilitated by seamless integrations with leading LLM tools such as Hugging Face Transformers, OpenAI functions, and the MLflow AI Gateway. Moreover, the integration with LangChain and the Prompt Engineering UI elevates the platform’s usability, simplifying model development processes specifically tailored for generating diverse AI applications.
This enhanced functionality caters to a spectrum of use cases encompassing chatbots, document summarization, text classification, sentiment analysis, and more, aligning MLflow as a versatile tool for fostering generative AI applications.
Benefits of MLflow
Model Development
Streamline and expedite the machine learning lifecycle through a standardized framework tailored for production-ready models. Managed MLflow Recipes empower effortless ML project initialization, swift iteration, and seamless deployment of large-scale models. Develop applications like chatbots, document summarization, sentiment analysis, and classification with remarkable ease. MLflow’s AI Gateway and Prompt Engineering, seamlessly integrated with LangChain, Hugging Face, and OpenAI, facilitate the development of generative AI apps.
 Experiment Tracking
Experiment Tracking
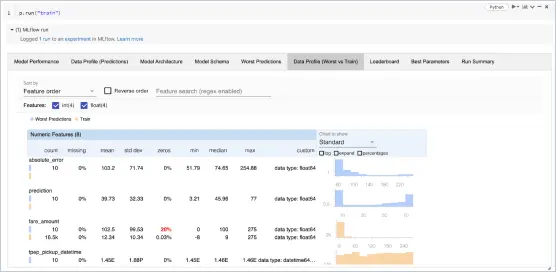 Experiment Tracking
Experiment TrackingExecute experiments using any ML library, framework, or language while automatically tracking each iteration’s parameters, metrics, code, and models. MLflow on Databricks ensures secure sharing, management, and comparison of experiment results, artifacts, and code versions. Its innate integration with the Databricks Workspace and notebooks simplifies this process.
Model Management
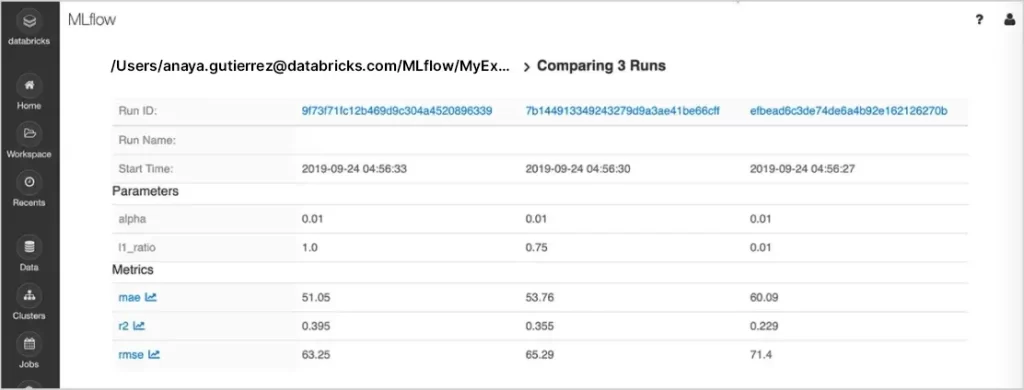 Model Management
Model ManagementCentralize the discovery and sharing of ML models, collaboratively transition models from experimentation to online testing and production, and integrate seamlessly with approval workflows, governance mechanisms, and CI/CD pipelines. Monitor the performance of ML deployments efficiently. The MLflow Model Registry fosters expertise-sharing knowledge dissemination and maintains operational control.
Model Deployment
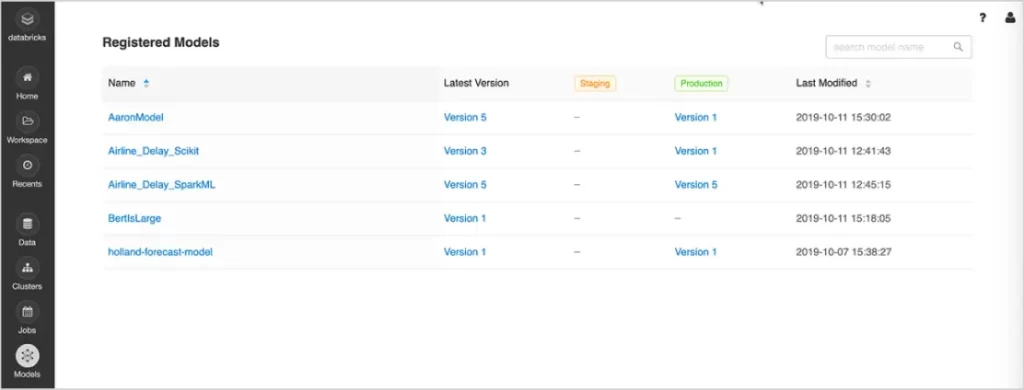 Model Deployment
Model DeploymentExpeditiously deploy production models for batch inference on Apache Spark or as REST APIs through integrated Docker containers, Azure ML, or Amazon SageMaker. I managed MLflow on Databricks, which enables the operationalization and monitoring of production models using the Databricks Jobs Scheduler and auto-managed Clusters, scaling dynamically to meet business requirements. The latest enhancements to MLflow streamline the packaging of generative AI applications for deployment. Now, deploying chatbots and other gen AI applications like document summarization, sentiment analysis, and classification at scale using Databricks Model Serving is more seamless than ever.
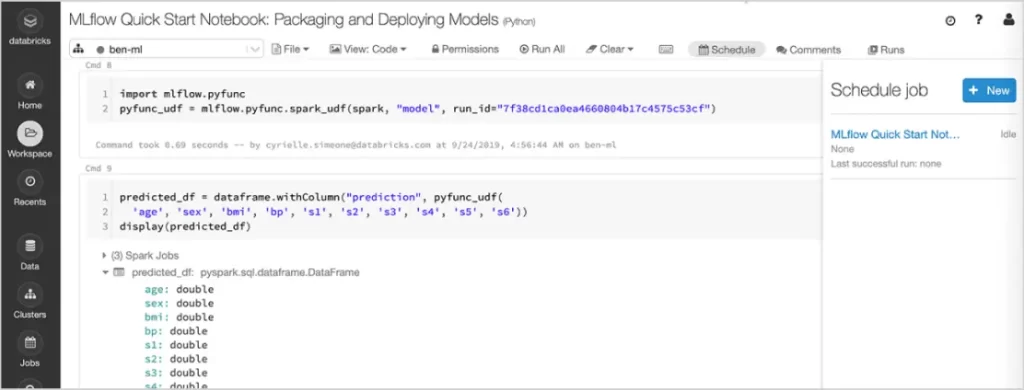
MLflow’s Key Components and Features
MLflow Tracking
- Automated Logging: Log parameters, code versions, metrics, and artifacts for each run using Python, REST, R API, and Java API.
- Prompt Engineering: Simplify model development for Gen AI applications like chatbots, document summarization, sentiment analysis, and classification. MLflow’s AI Gateway and Prompt Engineering, integrated with LangChain, offer a no-code UI for fast prototyping and iteration.
- Tracking Server: Instantly initiate logging of all runs and experiments in one place without configuration on Databricks.
- Experiment Management: Securely create, organize, search, and visualize experiments within the Workspace, complete with access control and search capabilities.
- MLflow Run Sidebar: Automatically track runs within notebooks and preserve snapshots of code versions for each run, facilitating easy access to previous iterations.
- Logging Data with Runs: Record parameters, datasets, metrics, artifacts, and more as it runs locally or remotely to a tracking server or an SQLAlchemy-compatible database.
- Delta Lake Integration: Track large-scale datasets used in model training through Delta Lake snapshots.
- Artifact Store: Store significant files such as models in repositories like S3 buckets, Azure Blob Storage, Google Cloud Storage, SFTP servers, NFS, and local file paths.
MLflow Models
- Standard Model Packaging: MLflow Models offer a standard format for packaging ML models that are usable across diverse downstream tools, enabling real-time serving through REST APIs or batch inference on Apache Spark.
- Model Customization: Utilize Custom Python Models and Custom Flavors for ML libraries not explicitly supported by MLflow’s built-in flavors.
- Built-in Model Flavors: MLflow provides standard flavors like Python and R functions, Hugging Face, OpenAI, LangChain, PyTorch, Spark MLlib, TensorFlow, and ONNX for diverse application needs.
- Built-in Deployment Tools: Swiftly deploy on various platforms, including Databricks via Apache Spark UDF, local machines, Microsoft Azure ML, Amazon SageMaker, and Docker Images.
MLflow Model Registry
- Central Repository: Register MLflow models in the Model Registry, assigning unique names, versions, stages, and metadata to each model.
- Model Versioning: Automatically track model versions and their updates within the registry.
- Model Staging: Assign preset or custom stages to model versions, reflecting their lifecycle stages like “Staging” and “Production.”
- CI/CD Workflow Integration: Seamlessly integrate stage transitions, request, review, and approval processes into CI/CD pipelines for better governance.
- Model Stage Transitions: Log registration events or changes as activities, automatically recording user actions, changes, and additional metadata.
MLflow AI Gateway
- LLM Access Management: Govern SaaS LLM credentials for controlled access.
- Cost Control: Implement rate limits to manage costs efficiently.
- Standardized LLM Interactions: Experiment with different OSS/SaaS LLMs using standard input/output interfaces for tasks like completions, chat, and embeddings.
MLflow Recipes
- Simplified Project Startup: MLflow Recipes provide pre-connected components for building and deploying ML models.
- Accelerated Model Iteration: Standardized, reusable steps in MLflow Recipes streamline model iteration, reducing time and costs.
- Automated Team Handoffs: Opinionated structure generates modularized, production-ready code, facilitating automatic transition from experimentation to production.
MLflow Projects
- Project-Specific Environments: Specify Conda environment, Docker container environment, or system environment for executing code within MLflow projects.
- Remote Execution Mode: Execute MLflow Projects from Git or local sources remotely on Databricks clusters using the Databricks CLI, ensuring scalability for your code.