
In the fast-evolving landscape of enterprise technology, the emergence of AI-driven assistants stands at the forefront, promising a paradigm shift in how businesses operate and thrive. This technological stride isn’t just about innovation; it’s about reshaping the fundamental fabric of how work gets done.

Large Language Models (LLMs) have become instrumental in enterprise operations, significantly enhancing productivity and enriching customer experiences. Their implementation or adoption, alongside the integration of AI chatbots, drives the future of enterprise work, steering it towards a realm where human and AI collaboration becomes the norm. NVIDIA recently hosted a webinar on December 13, 2023, centered around RAG and AI Chatbots, providing insights into NVIDIA’s approach to crafting AI Chatbots using RAG. The key speakers include Amanda Saunders, Senior Product Marketing Manager NVIDIA, and Jacob Liberman, Product Manager NVIDIA. The pivotal aspects discussed during the webinar offer a concise overview of the key insights shared by the key speakers addressed in the article.
AI-driven assistants, often categorized as chatbots, copilots, and agents, each play a distinct role in reshaping enterprise interactions:
- Chatbots: These AI tools engage in text-and-voice-based interactions, focusing primarily on question-and-answer tasks within defined parameters.
- Copilots: Unlike chatbots, copilots assist users in specific tasks such as writing, coding, or generating images. They actively contribute to task completion, exemplified by tools like Microsoft Copilot and Github Copilot.
- Agents: AI agents handle complex tasks and interactions by embracing a broader spectrum. Siri or Amazon Alexa are prime examples, showcasing the capability to manage multifaceted tasks beyond simple Q&A sessions.
Integrating these AI-driven assistants isn’t just a technological shift; it’s a strategic initiative driving the future of enterprise operations. They empower employees to transition from manual data gathering to orchestrating teams of LLMs, significantly enhancing efficiency and productivity across diverse job functions. With enterprises slated to house hundreds to thousands of these AI assistants across job functions, the shift is not merely towards automation but towards augmentation – enhancing human capabilities through symbiotic collaboration with AI entities.
Challenges of Language Model AIs (LLMs) in Enterprise Environments
It is crucial to delineate the nuanced challenges Language Model AIs face within these environments. While LLMs are powerful and automated tools, their deployment within enterprise ecosystems is not devoid of pitfalls, posing critical concerns for accuracy and reliability.
Outdated Data, Outdated Models
One of the primary impediments encountered with LLMs in enterprise settings is their susceptibility to the integrity of data sources. As data becomes outdated within enterprise repositories, the efficacy of LLM models diminishes proportionally. The dependency of these models on current and relevant data underscores the criticality of maintaining updated and real-time information sources to sustain their accuracy and functionality.
Risk of Data Hallucination
Moreover, the inherent nature of LLMs introduces the risk of data hallucination, a concern exacerbated within enterprise environments. This phenomenon occurs when models generate outputs based on erroneous or outdated information, leading to inaccurate insights or decisions. The ramifications of data hallucination within enterprise operations are profound, potentially skewing critical analyses and hindering informed decision-making processes.
Lack of Proprietary Knowledge Integration
Additionally, while LLMs possess formidable capabilities, their inherent limitation lies in the absence of proprietary knowledge integration. These models often lack direct access to or integration with proprietary enterprise knowledge repositories. Consequently, their responses or outputs may lack the depth and specificity demanded by enterprise-level queries, inhibiting their ability to provide comprehensive and contextually relevant insights.
NVIDIA’s Optimized RAG to Reconcile Power of LLMs
NVIDIA’s Optimized Retrieval Augmented Generation (RAG) bridges the gap between powerful LLMs and enterprise needs. It harnesses pre-trained LLMs, personalizes responses based on context, and delivers optimized inference through TensorRT, all while ensuring responsible use through guardrails. This comprehensive solution unlocks the real-world potential of LLMs for businesses.
NVIDIA’s Retrieval Augmented Generation transcends seeking the immense capabilities of Language Model AIs. Envision where AI dynamically tailors responses to customer inquiries, swiftly generates precise market reports, and seamlessly scales operations without excessive costs. RAG turns this vision into reality by harnessing pre-trained LLMs, optimizing inference processes, and ensuring ethical usage through embedded safeguards. This holistic solution unlocks the full potential of LLMs for enterprises, elevating operational efficiency, precision, and ethical AI integration, thereby paving the way for the future of AI in enterprise contexts, all empowered by NVIDIA’s innovative RAG.
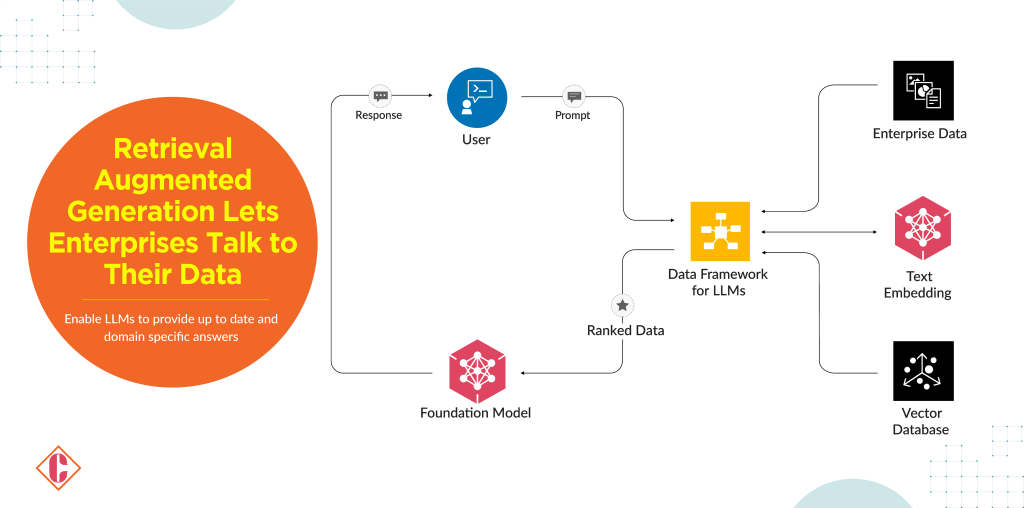
Key components of the RAG pipeline:
-
Data Framework: The foundation of RAG lies in its comprehensive data framework. Acting as the insatiable engine driving the LLM, this framework ingests and manages vast data volumes required for training and inference. NVIDIA’s RAPIDS platform facilitates efficient data preparation, while TensorFlow empowers GPU-accelerated processing, ensuring the LLM receives the necessary fuel for optimal performance.
-
Microservice for Embedding, Reranking, and Personalization: The core of RAG resides in this intelligent microservice. Leveraging pre-trained LLMs, likely further fine-tuned on domain-specific enterprise datasets, this microservice generates a spectrum of candidate responses. These responses are then subjected to rigorous refinement, employing reranking and personalization techniques based on user context, task requirements, and enterprise-specific factors. This ensures the final output aligns seamlessly with the user’s intent and domain context.
-
TensorRT-LLM: Optimized inference is the hallmark of RAG, achieved through the TensorRT-LLM engine. This technology leverages NVIDIA’s expertise in GPU optimization, enabling efficient and low-latency text generation on NVIDIA platforms. The result? Enterprises can experience significant performance gains while minimizing resource consumption, ultimately driving cost savings and scalability.
-
Guardrails: Responsible and ethical LLM utilization is a cornerstone of RAG’s design. This manifests through a robust system of guardrails, encompassing bias detection and mitigation, factual verification, and output monitoring. By implementing these safeguards, RAG ensures the trustworthiness and reliability of the generated responses, mitigating potential risks associated with large language models and fostering responsible AI practices within the enterprise.
-
Ranked Data: The culmination of the RAG pipeline is the delivery of ranked data. This signifies the LLM’s most relevant and accurate responses, tailored to the user’s query or task within the enterprise context. Ranked data empowers informed decision-making, streamlines workflows, and ultimately drives operational efficiency for enterprises embracing the power of LLMs.
Transformative Impact of RAG on LLM Integration
Improved LLM Performance and Efficiency
- Reduced Computation Costs: RAG harnesses pre-trained LLMs and optimizes inference using TensorRT, demanding less computational power and diminishing the expenses linked with LLM operations on enterprise infrastructure.
- Faster Response Times: Optimized inference translates to quicker response generation, enhancing user experience and enabling real-time decision-making.
- Enhanced Accuracy and Relevance: RAG tailors responses based on user context and task demands, resulting in more precise and pertinent outputs than conventional LLM generation.
Streamlined Workflows and Increased Productivity
- Automated Tasks and Data Analysis: LLMs adeptly handle repetitive tasks like data analysis and report generation, liberating human employees for more strategic endeavors.
- Personalized User Interactions: RAG customizes responses to customer queries, enriching satisfaction levels and augmenting customer service efficiency.
- Data-Driven Decision-Making: LLMs analyze extensive enterprise data, identifying trends and patterns, thereby empowering informed decision-making across organizational tiers.
Innovation and Competitive Advantage
- Unlocking New Use Cases: Integration of LLMs into existing enterprise applications fosters innovative functionalities and features.
- Enhanced Business Processes: LLMs optimize business procedures by automating tasks, identifying inefficiencies, and suggesting improvements.
- Staying Ahead of the Curve: Early adoption of LLMs provides a competitive edge by leveraging their potential to innovate and enhance operations.
Additional Benefits
- Scalability: The RAG architecture facilitates efficient scalability, enabling enterprises to manage voluminous data and user queries without compromising performance.
- Security and Privacy: Integration of LLMs aligns with enterprise security measures, safeguarding sensitive data.
- Responsible AI: RAG incorporates guardrails to mitigate bias, ensure factual accuracy, and monitor LLM outputs, fostering responsible and ethical AI practices within the enterprise.
Streamlined Approach for Building a Robust AI Chatbot for Deployment
Two key components emerge in exploring the development of highly adept AI chatbots tailored for the intricate landscapes of enterprise: pre-trained language models and domain-specific data. NVIDIA’s Retrieval Augmented Generation framework embodies this principle, offering a precise method for constructing resilient chatbots. RAG leverages pre-trained LLMs fine-tuned with enterprise data to deliver accurate, personalized responses. Its optimized inference on NVIDIA GPUs ensures efficient performance. This data-centric approach and iterative development empower businesses to continually enhance chatbots, unlocking their potential to streamline operations, enrich customer experiences, and drive competitive advantage. Let’s explore how RAG shapes the path for constructing the next generation of AI chatbots, transforming enterprise interactions.
 1. Determine POC Use Case
1. Determine POC Use Case
 1. Determine POC Use Case
1. Determine POC Use Case- Start with internal use cases with minimal data access and intellectual property concerns.
- Examples include support document analysis, corporate communications, employee experience tools, and sales communication.
- This initial step helps validate the chatbot’s value and gather user feedback before broader deployment.
2. Establish POC Environment Configuration
- Utilize existing cloud platforms or a dedicated environment to build and test the chatbot.
- Ensure the environment has data storage, training, and inference resources.
- Consider using NVIDIA’s AI workflow for step-by-step guidance in building generative AI chatbots.
3. Construct RAG Workflow
- Leverage NVIDIA’s Retrieval Augmented Generation (RAG) framework for efficient and accurate chatbot responses.
- RAG combines pre-trained LLMs with domain-specific data to personalize responses and improve accuracy.
- The workflow involves data ingestion, pre-processing, model training, and deployment on NVIDIA GPUs.
4. Assess Performance
- Use public benchmarks like MT-Bench to assess the chatbot’s performance on various tasks.
- Establish internal test sets based on specific use case requirements to gauge accuracy and latency.
- Use a combination of automated and human testing to ensure the chatbot performs as expected.
5. Expand Deployment Scale
- Based on successful POC testing, move the chatbot to production environments for broader use.
- Utilize cloud-based deployment for scalability and easy access.
- Continuously monitor and improve the chatbot’s performance through feedback loops and ongoing training.
NVIDIA AI Foundation Models and Endpoints: Optimizing Generative AI for Enterprise
NVIDIA AI Foundation Models and Endpoints are pivotal components tailored for enterprise-grade generative AI. These solutions facilitate seamless integration onto NVIDIA accelerated infrastructure, enabling a smooth transition to AI production environments.
Understanding NVIDIA AI Foundation Models and Endpoints
NVIDIA AI Foundation Models empower enterprises to attain peak performance by leveraging pre-trained generative AI models. This allows for expedited customization while capitalizing on the latest training and inference methodologies. Moreover, NVIDIA AI Foundation Endpoints facilitate the connection of applications to these models, operating on a fully accelerated stack and facilitating performance testing.
Building Tailored Generative AI Models for Enterprise Applications
The NVIDIA AI foundry service integrates NVIDIA AI Foundation Models, the NVIDIA NeMo™ framework, tools, and the NVIDIA DGX™ Cloud, offering enterprises a comprehensive solution for crafting custom generative AI models.
Commence with Leading Generative AI Models
Embark on your generative AI journey by leveraging leading foundation models, including Llama 2, Stable Diffusion, and NVIDIA’s Nemotron-3 8B family. These models are optimized to deliver the highest performance efficiency.
Fine-Tune and Personalize
Utilize NVIDIA NeMo to refine and test models using proprietary data, ensuring customizability tailored to your enterprise’s needs.
Streamlined Cloud-Based Model Development
Accelerate model development on DGX Cloud, a serverless AI-training-as-a-service platform for enterprise developers.
Benefits of NVIDIA AI Foundation Models and Endpoints
- Performance Optimization: Experience up to 4x faster inference, reducing Total Cost of Ownership (TCO) and boosting energy efficiency.
- Enterprise-Grade Solutions: Leverage lean, high-performing large language models sourced responsibly from datasets.
- On-the-Fly Model Testing: Access peak model performance directly from a browser through a user-friendly interface (GUI) or Application Programming Interface.
- Integration-Ready APIs: Connect applications seamlessly to API endpoints, ensuring real-world performance tests across fully accelerated infrastructures.
- Flexible Model Deployment: Use NVIDIA AI Enterprise capabilities to deploy models effortlessly across diverse environments, from the cloud to data centers and workstations.
FAQs
1. What are AI-driven assistants in the context of enterprise technology?
AI-driven assistants, categorized as chatbots, copilots, and agents, are intelligent tools utilizing AI to aid in various tasks within enterprise settings. They include text-and-voice-based interactions (chatbots), specific task assistance (copilots), and handling multifaceted tasks (agents).
2. How do AI-driven assistants impact enterprise operations?
These assistants empower employees by automating tasks, orchestrating large language models (LLMs), and enhancing productivity across different job functions. They signify a shift towards augmentation, complementing human capabilities through AI collaboration.
3. What challenges do Language Model AIs (LLMs) face in enterprise environments?
Challenges include reliance on updated data sources to maintain accuracy, the risk of generating outputs based on erroneous information (data hallucination), and limitations in integrating proprietary enterprise knowledge into responses.
4. What are the key components of NVIDIA’s RAG pipeline?
The components include a comprehensive data framework, a microservice for refining responses, TensorRT-LLM for optimized inference, guardrails for responsible AI, and the delivery of ranked data tailored to enterprise queries.
5. How does RAG impact LLM integration in enterprises?
RAG enhances LLM performance and efficiency, reduces computation costs, ensures faster response times, streamlines workflows, increases productivity, unlocks innovation, ensures scalability, and maintains security and responsible AI practices.
[To share your insights with us, please write to sghosh@martechseries.com]