
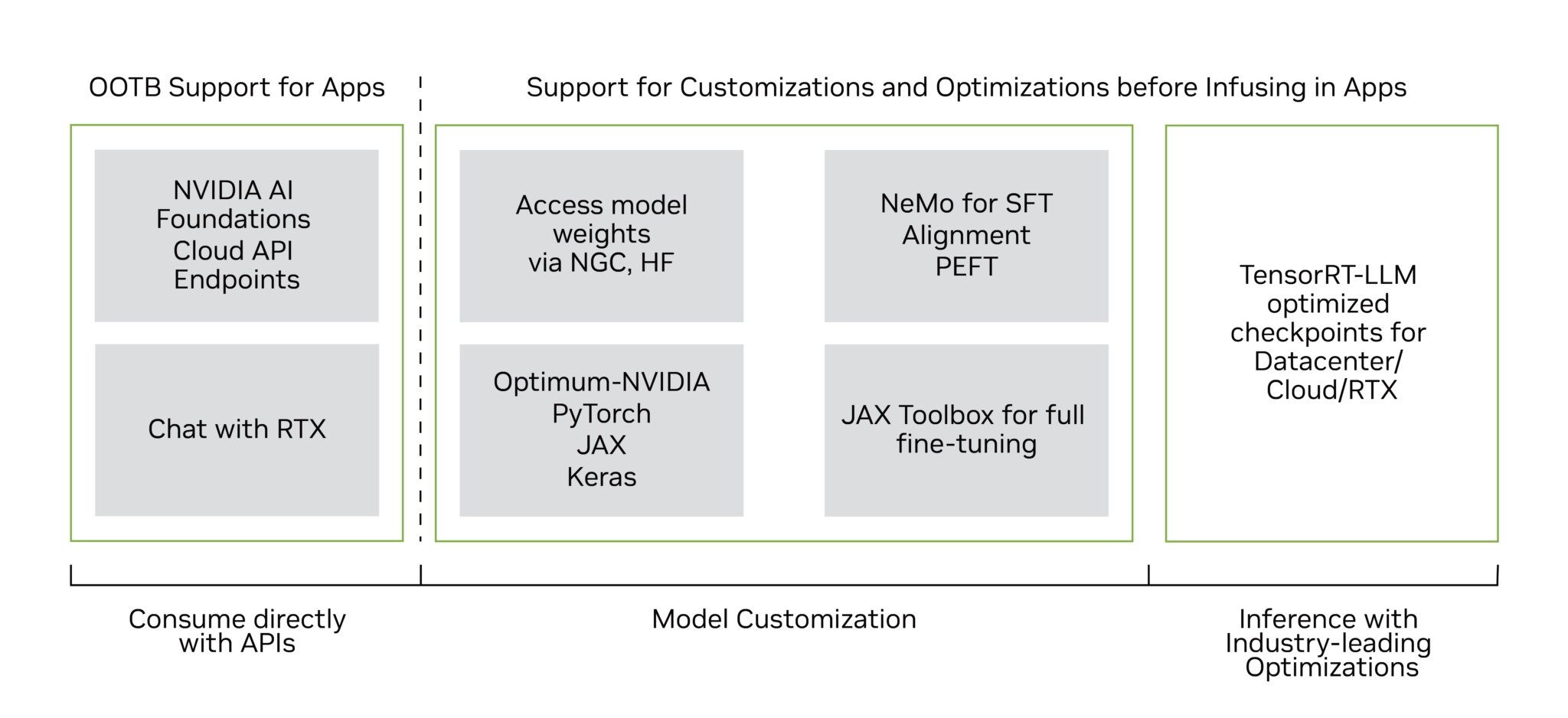
NVIDIA joins hands with Google to launch Gemma, an optimized set of open models derived from Gemini technology. Powered by TensorRT-LLM, Gemma offers high throughput and cutting-edge performance. It’s compatible across NVIDIA AI platforms, making it accessible from data centers to local PCs.
Developed by Google DeepMind, Gemma 2B and Gemma 7B models prioritize efficiency. Accelerated by TensorRT-LLM, Gemma ensures seamless deployment and optimization. TensorRT-LLM’s simplified Python API streamlines quantization and kernel compression, enhancing customization options for Python developers.
Gemma models, boasting a vocabulary size of 256K and supporting context lengths of up to 8K, prioritize safety. Extensive data curation and PII filtering ensure responsible AI practices. Trained on over six trillion tokens, Gemma enables developers to build and deploy advanced AI applications confidently.
 Accelerating Gemma Models with TensorRT-LLM
Accelerating Gemma Models with TensorRT-LLM
TensorRT-LLM plays a pivotal role in enhancing the speed of Gemma models. With its array of optimizations and kernels, TensorRT-LLM significantly improves inference throughput and latency. Notably, three distinct features—FP8, XQA, and INT4 Activation-aware weight quantization (INT4 AWQ)—contribute to boosting Gemma’s performance.
FP8 Enhancement:
FP8 represents a natural evolution in deep learning applications, surpassing the common 16-bit formats in modern processors. It facilitates higher throughput of matrix multiplication and memory transfers without compromising accuracy. FP8 benefits both small and large batch sizes, particularly in memory bandwidth-limited models.
FP8 Quantization for KV Cache:
TensorRT-LLM introduces FP8 quantization for the KV cache, addressing the unique challenges posed by large batch sizes or long context lengths. This optimization enables running batch sizes 2-3 times larger, thereby enhancing performance.
XQA Kernel:
The XQA kernel supports group query attention and multi-query attention, providing optimizations during generation phases and beam search. NVIDIA GPUs optimize data loading and conversion times, ensuring increased throughput within the same latency budget.
INT4 AWQ:
INT4 AWQ delivers superior performance with small batch size workloads, reducing a network’s memory footprint and significantly enhancing performance in memory bandwidth-limited applications. It leverages a low-bit weight-only quantization method to minimize quantization errors and protect salient weights.
Real-Time Performance with TensorRT-LLM
TensorRT-LLM, coupled with NVIDIA H200 Tensor Core GPUs, demonstrates remarkable real-time performance on Gemma 2B and Gemma 7B models. A single H200 GPU achieves over 79,000 tokens per second on the Gemma 2B model and nearly 19,000 tokens per second on the larger Gemma 7B model.
Enabling Scalability with TensorRT-LLM
Deploying the Gemma 2B model with TensorRT-LLM on just one H200 GPU allows serving over 3,000 concurrent users, all with real-time latency. This scalability underscores the efficiency and effectiveness of TensorRT-LLM in delivering high-performance AI solutions.