In the early days of computing, data was stored in hierarchical databases, rigid structures resembling a family tree, organized in a top-down manner. While effective for straightforward tasks, these systems struggled with the growing complexity of the digital landscape.
As businesses expanded and diversified, the need for more flexible data management became evident. The relational database model, introduced by Dr. Edgar F. Codd in the 1970s, revolutionized data storage by allowing it to be organized in tables. This innovation enabled the establishment of relationships between different data sets, facilitating unprecedented querying capabilities and valuable insights.
Fast forward to the 21st century, and the data landscape experienced another seismic shift. The advent of the internet and the proliferation of devices led to an explosion in data volume, variety, and velocity, overwhelming traditional databases. New frameworks, such as Hadoop, emerged to manage this data deluge.
As data continues to grow exponentially, managing and leveraging it to fuel AI and analytics has become increasingly complex. Data accumulates in various systems and formats, leading to isolation and inaccessibility, which hinders efficient management and actionable insights. Organizations face significant challenges in ensuring data consistency, security, and compliance across diverse data landscapes, often resulting in delayed decision-making and missed opportunities.
Despite the untapped potential in this ocean of data, many organizations lack a strategy to unlock its full value. A data fabric architecture offers a solution, addressing these challenges head-on and paving the way for more efficient data management and utilization.
Also Read: How Data Governance Drives Strategic Growth and Value
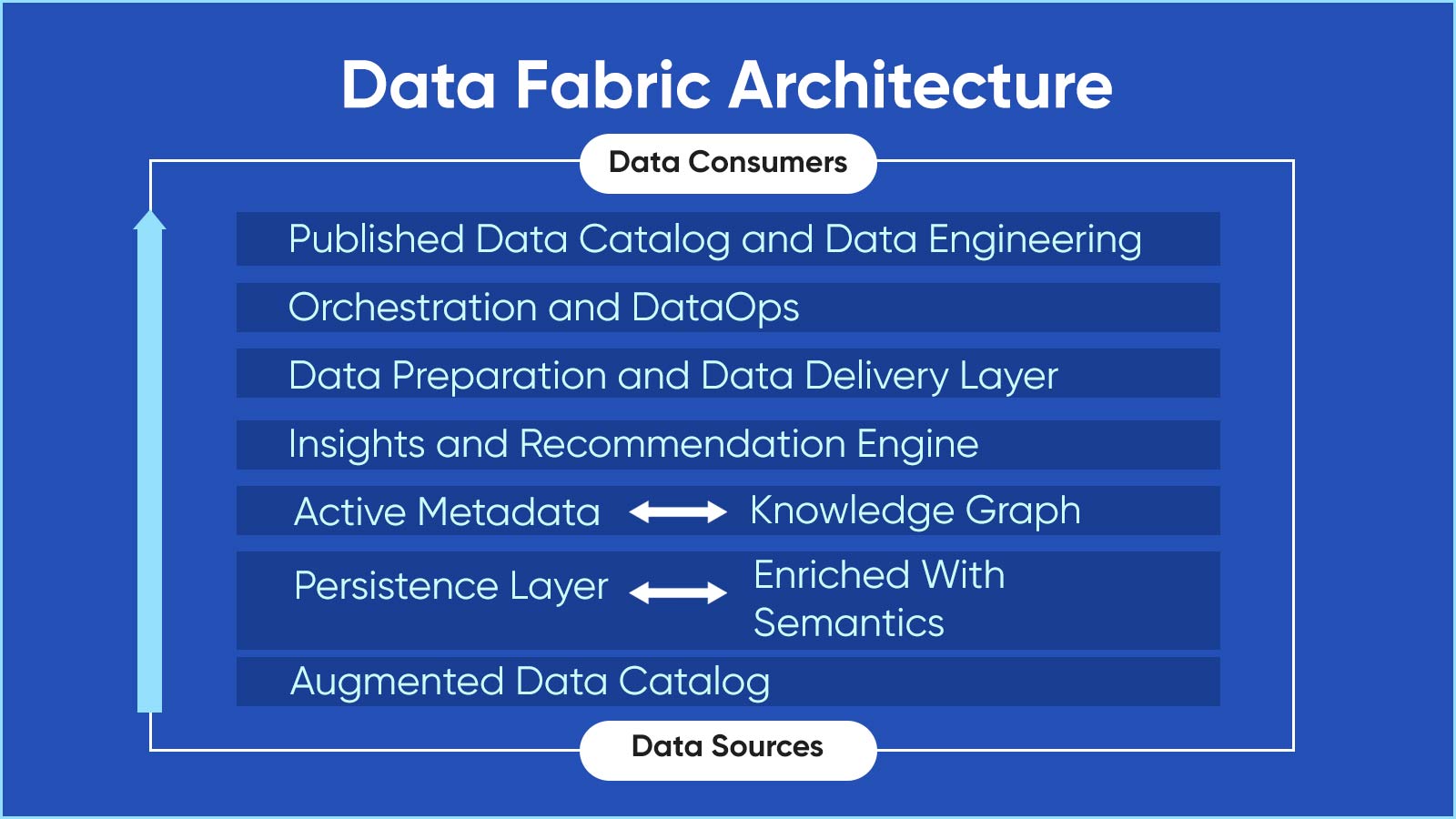
What is Data Fabric?
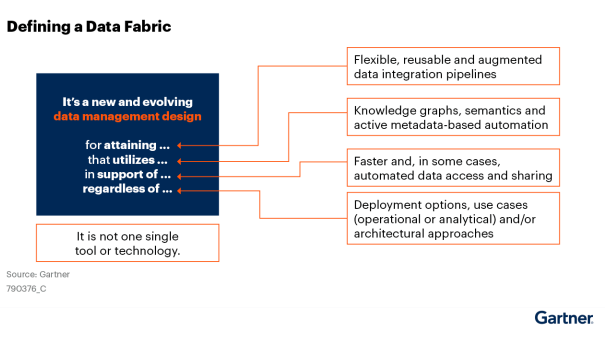
Gartner Defines: A data fabric is a data management design concept for attaining flexible, reusable and
augmented data pipelines and services in support of various operational and analytics use cases. Data fabrics support a combination of different data integration styles, and utilize active metadata, knowledge graphs, semantics and machine learning to augment data integration design and delivery.