Introduction
In the rapidly evolving field of artificial intelligence, the prevailing narrative often emphasizes that model size begets model quality. The assumption is that bigger models, trained on vast datasets, inherently deliver better performance. However, this mirrors past technological trends where size was mistakenly equated with capability—such as in the early mainframe era when computing power was measured by physical dimensions rather than efficiency. Today, a paradigm shift is occurring. Small language models (SLMs), when fine-tuned effectively, are demonstrating that they can surpass their larger counterparts in specific applications, offering significant advantages in cost, speed, and scalability.
Also Read: Quantum Computing In The Now
The Misconception of Size Over Substance
The belief that larger models are superior is deeply ingrained in the AI community. This perspective leads organizations to invest heavily in developing and maintaining LLMs, expecting that the sheer scale will translate to unmatched performance. However, this approach overlooks the practical challenges and diminishing returns associated with scaling. Much like the over-investment in cumbersome enterprise resource planning (ERP) systems in the early 2000s—which promised comprehensive solutions but often resulted in bloated, inefficient infrastructures—the focus on size can overshadow the importance of optimization and adaptability.
Why Bigger Isn’t Always Better
Large models come with significant drawbacks: they require enormous computational resources, are costly to train and maintain, and often lack the agility needed for specialized tasks. The complexity of these models can lead to inefficiencies, making them less practical for real-world applications where speed and cost-effectiveness are critical. This situation is akin to the supercomputer race of the past, where the pursuit of maximum computational power often ignored the practical needs of most users.
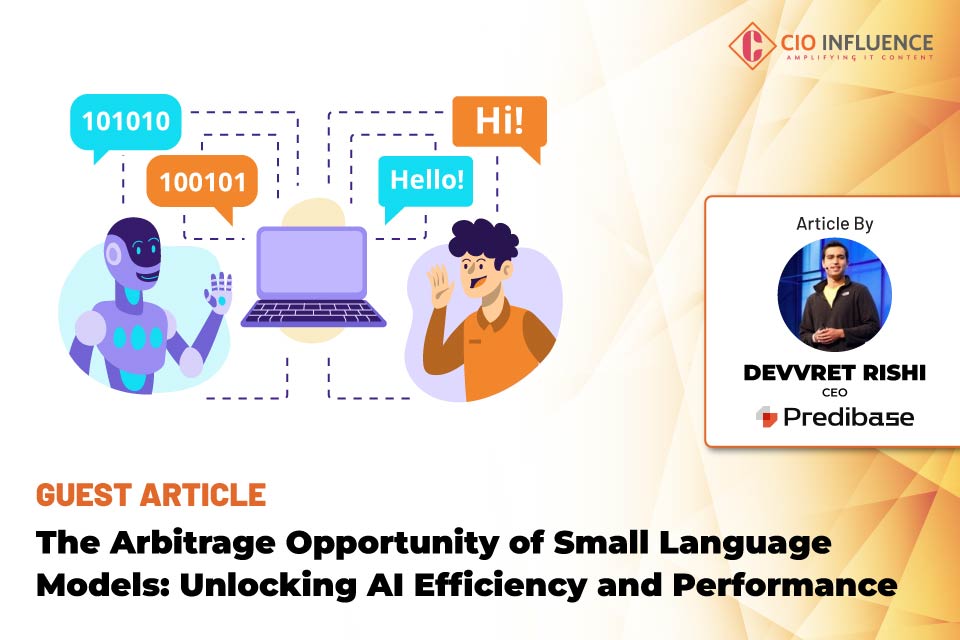
The Emergence of Small Language Models
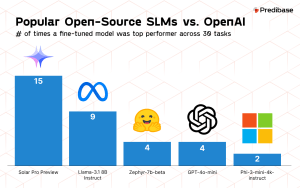
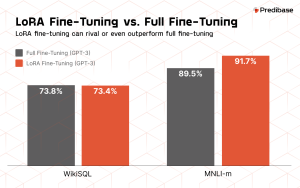
SLMs are challenging the status quo by offering a more efficient alternative. Through techniques like Low-Rank Adaptation (LoRA), which involves fine-tuning a small subset (less than 1%) of a model’s parameters, SLMs can achieve performance levels comparable to fully customized models. This approach drastically reduces the resources required for training and deployment. It’s reminiscent of the shift towards microservices in software architecture, where breaking down applications into smaller, manageable pieces led to greater flexibility and scalability.
 The Importance of Robust Infrastructure
The Importance of Robust Infrastructure
 The Importance of Robust Infrastructure
The Importance of Robust InfrastructureFine-tuning alone isn’t sufficient to realize the full potential of SLMs. A reliable and scalable infrastructure is essential to bring these models into production and maintain their performance at scale. A well-designed inference stack ensures that models operate efficiently, scale seamlessly, and meet enterprise requirements without compromising speed, security, or cost-effectiveness.
Also Read: A Comprehensive Guide to DDoS Protection Strategies for Modern Enterprises
Key Infrastructure Requirements
- Multi-Model Serving: Enabling multiple fine-tuned models to operate on a single GPU is critical for reducing costs and enhancing scalability. Utilizing frameworks that optimize GPU usage negates the need for separate hardware for each model. This streamlined approach allows for the deployment and management of domain-specific models with reduced complexity, facilitating the simultaneous handling of diverse applications.
- GPU Autoscaling: A robust inference stack should incorporate GPU autoscaling to align resource availability with fluctuating demands. Autoscaling adjusts GPU capacity up during high demand to sustain performance and scales it back to minimal levels during quieter periods, thus lowering operational costs. This adaptability ensures that organizations only incur costs for the resources they actively utilize, optimizing budget allocation and maintaining peak performance.
- Fast Throughput: Speed is crucial in processing inference workloads. Enhancements such as speculative decoding and FP8 quantization can significantly increase throughput—up to four times that of standard models—delivering swift, cost-effective performance. These improvements are particularly vital for applications that demand immediate responses, including customer support interfaces, fraud detection mechanisms, or automated document processing systems.
- Enterprise Readiness: An inference infrastructure must be designed to meet the demands of contemporary business environments, emphasizing scalability, security, and adaptability. Features such as multi-cloud capabilities prevent vendor lock-in, while Virtual Private Cloud (VPC) deployments offer additional data protection. Adhering to standards like SOC II is crucial for ensuring data security and client trust. Furthermore, ensuring high availability across multiple regions is critical to minimize service interruptions and provide low-latency responses, enabling users to access services from the nearest locations.
Building and maintaining this type of infrastructure can be complex and resource-intensive, requiring expertise in orchestration, GPU management, and model optimization. However, with the right tools and platforms, organizations can overcome these challenges.
Real-World Impact: Case Studies of Checkr and Convirza
Real-world examples illustrate how enterprises can unlock the full potential of fine-tuned SLMs with the right combination of infrastructure and customization.
- Checkr: This company fine-tuned small language models for background checks. As a result, Checkr achieved higher accuracy and lower latency in their processes. Remarkably, they realized a 5x reduction in costs compared to traditional LLM approaches. By focusing on fine-tuned SLMs, Checkr optimized their services, delivering faster and more reliable background checks to their clients while significantly cutting operational expenses.
- Convirza: Convirza deployed nearly 60 fine-tuned adapters on a single base model deployment that scales from zero to ten GPUs based on demand. This strategy reduced infrastructure costs by 10x. By efficiently managing resources and utilizing autoscaling, Convirza maintained high performance during peak times without incurring unnecessary expenses during low-demand periods, demonstrating the scalability and cost-effectiveness of fine-tuned SLMs.
These companies faced common challenges: the need for faster, more accurate models while keeping infrastructure costs manageable. By adopting smaller, fine-tuned models and leveraging advanced infrastructure solutions, they overcame the limitations of larger, open-source models and deployed domain-specific solutions that outperformed more resource-intensive alternatives.
The Strategic Advantage of SLMs
The success stories of Checkr and Convirza highlight a broader trend. SLMs offer a tactical edge by providing:
- Cost Efficiency: Reduced computational requirements translate to lower operational costs, making AI solutions more accessible and sustainable.
- Scalability: Fine-tuned models can be scaled up or down quickly, adapting to changing business needs without significant overhead.
- Performance Optimization: Tailoring models to specific domains enhances accuracy and relevance, improving user experience and outcomes.
The Broader Industry Implications
Adopting SLMs is not just about solving immediate technical challenges; it’s a strategic move that positions organizations for future growth. As AI continues to integrate into various aspects of business operations, the ability to deploy efficient, scalable, and cost-effective models becomes a competitive advantage.
Companies that recognize the limitations of relying solely on LLMs are better equipped to navigate the rapidly changing technological landscape. They can respond more quickly to market demands, innovate with agility, and allocate resources more effectively.
Conclusion
The landscape of AI is shifting. The focus is moving away from the pursuit of larger models towards the strategic deployment of smaller, more efficient ones. SLMs, supported by robust infrastructure, offer a compelling combination of performance, cost-effectiveness, and scalability. They challenge the notion that bigger is better, demonstrating that innovation often lies in optimizing what we have rather than expanding it indiscriminately.
As businesses continue to seek AI solutions that align with their operational needs and financial constraints, the adoption of fine-tuned SLMs is poised to accelerate. Companies that recognize and embrace this shift will be better positioned to lead in their industries, leveraging AI that is not just powerful but also practical and sustainable.