
Google Cloud AI Researchers have introduced LANISTR to tackle the challenges of managing unstructured and structured data within a framework. Multimodal data, which includes language, images, and structured data, is increasingly important in machine learning. The main challenge is handling missing data types in large, unlabeled datasets like tables and time series. Traditional methods often falter when data types are absent, resulting in poor model performance.
Most current multimodal data pre-training methods require all data types to be present during training and inference, which is rarely feasible in real-world scenarios. These methods, involving early and late fusion techniques, combine data from different modalities at the feature or decision level. However, they struggle with incomplete or missing data.
Also Read: Top 10 Anomaly Detection Software for Secured Enterprise
What is LANISTR?
LANISTR is a new framework designed for multimodal learning. It integrates unstructured (images, text) and structured (time series, tabular) data, aligning and fusing these data types to generate class predictions.
While recent breakthroughs in multimodal learning have focused on unstructured data such as vision, language, video, and audio (e.g., Flamingo, PaLI, CLIP, VATT), integrating structured data like tables and time series has been less explored. Many scenarios, such as healthcare diagnostics and retail demand forecasting, require structured and unstructured data. LANISTR addresses this need by learning joint representations of these disparate data types through a unified architecture and unique pretraining strategies.
LANISTR Model Architecture
The LANISTR architecture comprises modality-specific encoders and a multimodal encoder-decoder module for fusion. The language, image, and structured data encoders process the raw inputs. Depending on the dataset, there exist separate structured data encoders for tabular and time-series data. All the encoders are based on attention.
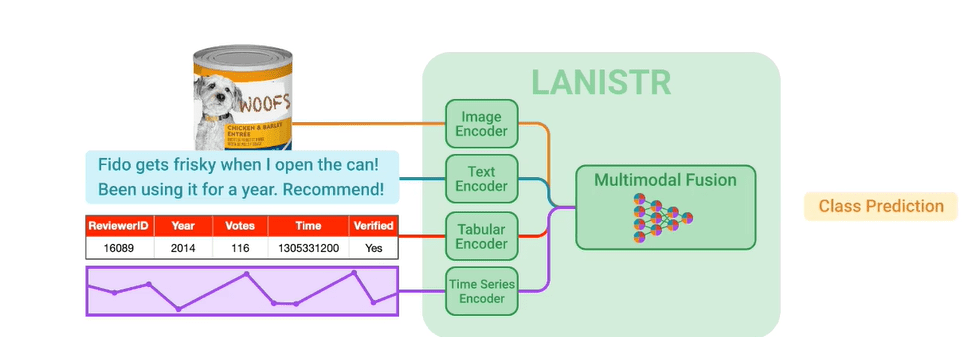 Encoded inputs are projected using modality-specific encoders with a single-layer projection head. The embeddings are then concatenated and fed into the multimodal fusion module.
Encoded inputs are projected using modality-specific encoders with a single-layer projection head. The embeddings are then concatenated and fed into the multimodal fusion module.
LANISTR applies cross-attention to learn meaningful representations that reflect cross-modal interactions. The fusion encoder, with six Transformer layers, captures cross-modal relationships.
Multimodal Masking and Evaluation
Multimodal masking in LANISTR involves masking entire data modalities during training. For example, one or two modalities might be randomly masked in datasets with text, images, and structured data. The model then learns to predict these masked modalities using the available data. This process is guided by a similarity-based objective, ensuring the generated representations for the missing modalities align coherently with the present data.
The efficacy of LANISTR was tested on two real-world datasets: the Amazon Product Review dataset from the retail sector and the MIMIC-IV dataset from the healthcare sector. LANISTR demonstrated robustness in out-of-distribution scenarios, effectively handling data distributions not seen during training. This capability is essential for real-world applications where data variability is common. LANISTR significantly improved accuracy and generalization, even with limited labeled data.
Benefits
- Multimodal Masking: utilizes multimodal masking to handle missing modalities in datasets, ensuring robust pretraining even with incomplete data.
- Enhanced Training: improves model efficacy and coherence with available data by training the model to predict masked modalities.
- Improved Robustness: demonstrates effectiveness in out-of-distribution scenarios, enhancing model robustness to unseen data distributions commonly encountered in real-world applications.
- Generalization: achieves significant gains in accuracy and generalization, even with limited labeled data, making it adaptable to various data environments.
- Addressing Critical Challenges: addresses the challenge of missing modalities in large-scale unlabeled datasets, a critical issue in multimodal machine learning.
- Efficient Pretraining: With novel masking strategies and a similarity-based objective, LANISTR enables efficient pretraining, laying a strong foundation for multimodal learning.
- Effective Learning from Incomplete Data: effectively learns from incomplete data, contributing to its ability to generalize well to new, unseen data distributions.
- Advancing Multimodal Learning: is a valuable tool for advancing multimodal learning, offering solutions to complex challenges.
Conclusion
In a nutshell, LANISTR tackles a huge issue in multimodal machine learning: dealing with missing data types in large unlabeled datasets. By using innovative unimodal and multimodal masking techniques and a similarity-based objective, LANISTR allows for strong and efficient pretraining. The results indicate that LANISTR learns effectively from incomplete data and adapts well to unseen data distributions. Overall, LANISTR proves to be a great resource for developing multimodal learning techniques.
FAQs
1. What is multimodal learning, and why is it important?
Multimodal learning involves integrating different data types, such as language, images, and structured data, to enhance machine learning models’ understanding. It is crucial as it reflects real-world scenarios where information comes in various forms.
2. What challenges does multimodal learning face?
One major challenge is handling missing data types in large, unlabeled datasets, such as tables and time series. Traditional methods struggle when certain data types are absent, resulting in decreased model performance.
3. How does LANISTR handle missing data types during training?
LANISTR applies multimodal masking, where all data modalities are masked during training. The model learns to predict these masked modalities using available data, guided by a similarity-based objective. This ensures coherent representations even with missing data.
4. How was LANISTR evaluated, and what were the results?
LANISTR was evaluated on real-world datasets from different sectors, demonstrating robustness and effectiveness in handling diverse data distributions. It achieved significant gains in accuracy and generalization, highlighting its adaptability and performance even with limited labeled data.
5. What does LANISTR mean for the future of multimodal learning?
LANISTR serves as a valuable tool for advancing multimodal learning techniques, offering solutions to complex challenges. Its efficient pretraining and effective learning from incomplete data contribute to its potential to drive innovation in the field.
[To share your insights with us as part of editorial or sponsored content, please write to sghosh@martechseries.com]