
Defining RAG: Retrieval Augmented Generation
Generative artificial intelligence (AI) is proficient in crafting text responses using large language models (LLMs) trained on extensive datasets. These responses are typically coherent and comprehensive, offering detailed insights applicable to posed questions, often termed prompts. Retrieval augmented generation (RAG) strategies further enhance the capabilities of AI systems by incorporating retrieval mechanisms to augment the generated responses with relevant information retrieved from external knowledge sources.
However, a notable drawback lies in the limitations of the formation used for generating responses, primarily derived from the LLM training data. This data could be outdated and lacking real-time relevance. They may not encompass specific organizational details, potentially resulting in inaccurate responses—such inaccuracies stakeholders mine stakeholder confidence in the technology, affecting. g customers and employees.
Enter retrieval augmented generation (RAG) is a sophisticated natural language processing (NLP) technique among the strengths of return- and generative-based AI models. RAG AI capitalizes on existing knowledge while possessing the ability to synthesize and contextualize information, thereby generating bespoke, contextually-aware responses, instructions, or explanations in human-like language. Unlike generative AI, RAG operates as a superset, incorporating the strengths of both generative and retrieval AI mechanisms.
Also Read: NVIDIA’s Role in Utilizing RAG for Advanced AI Chatbot Development in Enterprises
Significance of RAG in Modern IT Landscape
RAG models enhance factual grounding by leveraging external knowledge sources, ensuring responses are based on accurate information, thereby reducing the risk of generating misleading content. Secondly, RAG boosts contextual understanding by accessing relevant context from retrieved information. This enables the models to develop more nuanced and informative responses tailored to specific user queries and situations. Lastly, RAG facilitates improved adaptability through seamless integration with domain-specific knowledge bases. This allows models to adapt to various contexts and industries without requiring extensive retraining, thus enhancing their versatility and effectiveness in diverse settings.
Purpose and Scope of the Article
Evolution of Information Retrieval Systems
Information retrieval (IR) systems have undergone significant transformation over the years, continually adjusting to the expanding volume and complexity of information. Within this evolving landscape, RAG technology represents a recent advancement.
How RAG Got Its Name
Patrick Lewis, the lead author of the 2020 paper that coined the term, expressed regret over the unflattering acronym now representing a growing family of methods across numerous papers and commercial services, which he believes embody the future of generative AI.
“We definitely would have put more thought into the name had we known our work would become so widespread,” Lewis mentioned in an interview from Singapore, where he shared his ideas with a regional conference “f database developers.
“We always planned to have a nicer sounding name, but when it came time to write the paper,” one had a better idea,” explained Lewis, who currently heads an RAG team at AI startup Cohere.
Core Components and Functionality of RAG Solutions
- Retrieval: RAG systems employ various techniques to retrieve relevant information from external knowledge sources such as databases, documents, or web crawls. This retrieved information serves as the factual foundation for the subsequent generation process.
- Augmentation: The retrieved information is utilized to augment the context for a large language model (LLM), which may involve providing summaries, key points, or relevant data to inform the LLM’s generation process.
- Generation: Finally, the LLM leverages the augmented context to generate a response or complete a task tailored to the specific benefits or query and benefit from the factual grounding the retrieved information provides.
Key Features and Advantages of RAG Over Traditional Methods
- Improved Accuracy: By grounding responses in factual information from external sources, RAG significantly enhances the accuracy and factuality of LLM outputs compared to traditional methods reliant solely on internal training data.
- Enhanced Relevance: RAG enables LLMs to better grasp the context of a query or task by supplying relevant information sources, resulting in more focused and pertinent resources that address the user’s specific needs.
- Increased Adaptability: RAG facilitates seamless integration with domain-specific knowledge bases, allowing LLMs to adapt to various contexts and industries without extensive retraining, enhancing their versatility and efficiency.
- Reduced Bias: Relying on external knowledge sources, RAG can potentially mitigate presence within the LLM’s training data, leading to fairer and more objective outputs.
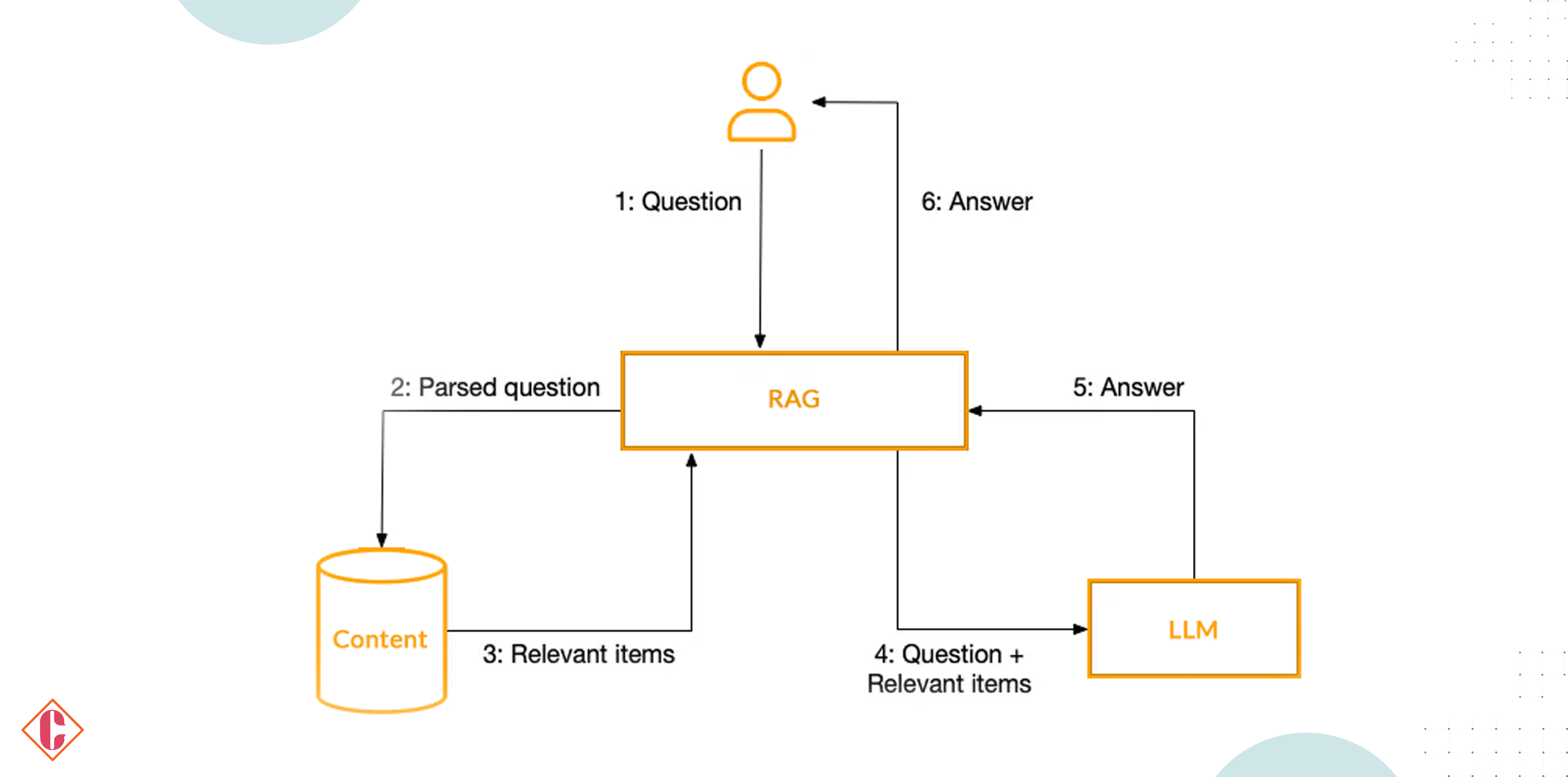
The Functionality of RAG Systems
Active RAG systems dynamically fetch information from external sources like databases, the internet, and real-time document sets in isn’ttime. This process isn’t merely passive retrieval; it’s an active user based on the user’s query or conversation context. The system utilizes this retrieved data to inform and shape the responses it generates. The key components of active RAG include:
- Dynamic Information Retrieval: Active RAG systems continuously search for and update their external knowledge sources, ensuring the information they use is current and relevant.
- Context-Aware Processing: The system comprehends and analyzes the context of a query, allowing it to retrieve information relevant to the user’s needs.
- Integration with LLMs: The retrieved information seamlessly integrates into the generative process of LLMs, accurate and not only accurate but also naturally phrased.
 Bridging the Knowledge Gap
Bridging the Knowledge Gap
Generative AI, powered by LLMs, generates text responses based on extensive training data. However, this reliance on static training data presents a significant drawback. As time passes, the information within the model becomes outdated, especially in dynamic environments like corporate chatbots. The absence of real-time or organization-specific data can result in inaccurate responses, eroding user trust, particularly in customer-centric or mission-critical scenarios.
Retrieval Augmented Generation
Retrieval Augmented Generation addresses this challenge by integrating the generative capabilities of LLMs with real-time, targeted information retrieval, all without altering the underlying model. This integration enables the AI system to deliver contextually appropriate responses based on current data. For example, while an LLM might offer generic information in a sports league context, RAG can provide real-time updates on recent games or player injuries by accessing external data sources like databases and news feeds.
Data that Stays Up-to-Date
RAG’s heart is its ability to enrich the LLM with fresh, domain-specific data, ensuring its knowledge repository remains current. This continuous updating process is cost-effective for keeping the generative AI relevant. Additionally, it adds a layer of context missing in generalized LLMs, thereby enhancing response quality. Furthermore, the capability to identify, correct, or remove incorrect information within RAG’s knowledge repository establishes a self-correcting mechanism for more accurate information retrieval.
Key Players Supporting the Creation of RAG Applications
AWS
While not offering a dedicated RAG solution, AWS provides various cloud services and machine learning tools that can be used to build and deploy custom RAG applications.
Microsoft Azure
Offers functionalities and resources that can be utilized to develop and integrate RAG models within Azure cloud services.
Databricks
Offers a comprehensive platform for deploying and managing various AI models, including RAG. Their platform provides tools for data preparation, model training, and integration with existing workflows.
DataStax
A leader in Gen AI data is making significant strides in advancing the technology through its RAGStack solution. Its collaboration with LlamaIndex provides a curated Python distribution and integration with various databases and enhanced indexing and parsing capabilities through LlamaParse, explicitly addressing the challenges of handling complex PDFs often encountered in business settings.
DeepMind
Owned by Google, DeepMind has developed its own RAG model with promising results in various tasks. While not publicly available, their research contributes significantly to the advancement of RAG technology.
OpenAI
Offers a publicly available RAG model and accompanying code, allowing developers to experiment and build custom applications.
Haystack
Provides an open-source framework designed explicitly for building question-answering and search applications using RAG models. It offers pre-trained models, data preparation tools, and integration functionalities.
Also Read: DataStax and LlamaIndex Partner to Simplify RAG Application Development for GenAI Developers
Applications of RAG in IT, Cloud Computing, and InfoSec
IT Applications:
- Enhanced Chatbots and Virtual Assistants: According to a study by Microsoft Research, RAG-powered chatbots displayed a 20% enhancement in user satisfaction compared to traditional rule-based chatbots, attributing this improvement to their capacity for providing more informative and contextually relevant responses.
- Streamlined Content Creation: As per a Gartner report, it is projected that by 2025, 30% of organizations will embrace AI-powered content creation tools. This may include RAG technology, valued for its capability to generate diverse content formats based on retrieved information and specific requirements.
- Efficient Knowledge Management: An IBM case study illustrated how RAG was utilized to develop a knowledge base for customer service representatives, resulting in a 35% reduction in average handling time due to the improved accessibility and searchability of relevant information.
Cloud Computing Applications:
- Optimized Resource Management: A research paper from the University of California, Berkeley, proposed a RAG-based approach for cloud resource allocation, showcasing a 15% reduction in cloud resource costs compared to traditional methods.
- Enhanced SecuritNetworks’ing: Palo Alto NetworksRAG’ste paper discusses RAG’s potential for security log analysis, emphasizing its ability to strengthen threat detection accuracy by 10% by incorporating context from external threat intelligence sources.
- Streamlined Cloud Migration: McKinsey & Company identifies RAG as a potential technology for optimizing cloud migration planning by analyzing dependencies and suggesting best practices based on retrieved information.
InfoSec Applications:
- Improved Phishing Detection: A study by the University of Washington evaluated RAG for phishing detection, achieving a 25% reduction in false favorable rates compared to traditional machine learning models.
- Automated Incident Response: An Amazon Web Services (AWS) SecuRAG’s blog post explores RAG’s potential for incident response. It suggests its use for analyzing security incidents and recommending mitigation strategies based on retrieved information from SIEM systems.
- Enhanced Security Awareness Training: Gartner predicts in a report that by 2025, 60% of security awareness training will be personalized, potentially leveraging RAG to tailor content based on individual user roles and retrieved information on relevant threats.
RAG Implementation Strategies and Best Practices
- Data Quality and Relevance: The effectiveness of RAG heavily relies on the quality of the retrieved data. Ensuring the relevance and accuracy of the data in the knowledge base is paramount. For example, developing an RAG system for a fiscal advice chatbot must include verified medical journals and publications as data sources. Utilizing outdated or non-peer-reviewed sources could result in inaccurate medical advice.
- Fine-Tuning for CoIt’stual Understanding: It’s crucial to fine-tune the generative models to effectively understand and utilize the context provided by the retrieved data. For instance, in a travel recommendation system, the RAG should recover data about destinations and grasp the context of queries, such as “family-friendly places in Europe in winter.” This ensures that the suggestions offered are contextually appropriate.
- Balancing Retrieval and Generation: Striking a balance between the retrieved information and the creative input of the generative model is essential to maintain the originality and value of the output. For example, in a news summarization tool, the RAG system should retrieve accurate news details while generating concise summaries that retain the essence of the news without overly relying on the retrieved text.
- Ethical Considerations and Bias Mitigation: Given the reliance on internal data sources, it’s crucial to consider ethical implications and actively work to mitigate biases in the retrieved data. For instance, if your RAG system is used for resume screening, ensure that the data it learns from does not contain biases against specific demographics. Regularly updating the data pool to represent diverse candidates is essential.
Leveraging RAG for Operational Excellence and Enhanced Customer Service
Company Profiles:
- JetBlue: Renowned for its commitment to customer satisfaction, JetBlue sought to enhance its internal operations and customer service capabilities.
- Chevron Phillips Chemical: Focusing on process optimization, Chevron Phillips Chemical aimed to automate document processes for increased efficiency.
- Thrivent Financial: Seeking to improve search functionality and productivity, ThriRAG’s Financial explored RAG’s potential for various applications within its organization.
Implementation of “RAG:
- JetBlue: Deployed “BlueBot,” a chatbot powered by open-source generative AI models and corporate data, enabling role-governed access to information across teams.
- Chevron Phillips Chemical: Utilized RAG for document process automation, streamlining workflows, and reducing manual efforts.
- Thrivent Financial: Explored RAG for improving search functionality, summarizing insights, and enhancing engineering productivity within its operations.
Benefits of RAG Implementation:
- Provision of up-to-date and accurate responses.
- Reduction of “inaccurate responses or hallucinations.”
- Delivery of domain-specific and relevant answers.
- Enhanced efficiency and cost-effectiveness across various use cases.
Technological Processes Behind RAG:
- Data sourcing and preparation.
- Chunking and text-to-vector conversion.
- Establishing critical links between source data and embeddings.
Best Practices for RAG Implementation:
- Emphasis on data quality and regular updates.
- Continuous evaluation and improvement of output.
- Seamless end-to-end integration within the existing system.
In a Nut Shell
Retrieval Augmented Generation (RAG) represents a transformative approach for Chief Information Officers (CIOs) seeking to unlock the full potential of data retrieval. RAG empowers organizations to deliver accurate, contextually-aware responses tailored to specific user queries and scenarios by seamlessly integrating generative AI with real-time information retrieval. From enhancing operational efficiency to elevating customer service experiences, RAG emerges as a strategic asset for CIOs navigating the complexities of modern IT landscapes. Harnessing the data retrieval potential of RAG enables CIOs to stay ahead of the curve, driving innovation and business success in an increasingly data-driven world.
FAQs
1. How does RAG differ from traditional LLMs like ChatGPT?
While conventional LLMs like ChatGPT demonstrate notable effectiveness, they are confined by the dataset used for training, akin to a chef limited to the ingredients in their pantry. In contrast, RAG modes” s incorporate a unique “retrieval” component, acting as a sous chef constantly sourcing fresh ingredients (information) to enhance their responses. This distinctive feature enables RAG models to deliver more precise and informative answers, especially when dealing with complex or open-ended queries.
2. Will RAG AI replace traditional LLMs?
Not necessarily. Both RAG and traditional LLMs have their strengths and weaknesses. RAG models excel in tasks requiring access to real-world information and accuracy, whereas traditional LLMs may perform faster or better in creative assignments. Ultimately, the choice depends on the specific requirements of the task, similar to selecting the right tool. Just as you wouldn’t use the same tool for every job, RAG and traditional LLMs are different tools in the AI toolbox, each suited for various scenarios.
3. How can CIOs integrate RAG into existing IT infrastructures and workflows effectively?
CIOs can effectively integrate RAG into existing IT infrastructures and workflows by:
- Conducting thorough assessments to identify areas where RAG can add value.
- Collaborating with IT teams and stakeholders to ensure seamless integration.
- Providing adequate training and resources for employees to adapt to RAG technologies.
- Regularly evaluating and optimizing RAG implementations to meet evolving business needs.
4. What challenges or considerations should CIOs know when adopting RAG solutions within their organizations?
Some challenges or considerations to be aware of when adopting RAG solutions include:
- Ensuring data quality and relevance for effective information retrieval.
- Fine-tuning generative models to understand and utilize context effectively.
- Balancing retrieval and generation to maintain originality and value in outputs.
- Addressing ethical implications and mitigating biases in retrieved data.
- Ensuring seamless integration and continuous evaluation for optimal performance.
[To share your insights with us as part of editorial or sponsored content, please write to sghosh@martechseries.com]