
The perception of data as a critical corporate asset for informed decision-making, enhanced marketing strategies, streamlined business operations, and cost reduction has intensified. The primary objective remains to amplify revenue and profits. However, inadequate data management practices can burden organizations with disparate data silos, inconsistent datasets, and quality issues. These shortcomings impede the utilization of business intelligence and analytics tools, potentially resulting in flawed insights.

Simultaneously, escalating regulatory compliance mandates, notably data privacy laws like GDPR and the California Consumer Privacy Act (CCPA), have amplified the significance of robust data management practices. Moreover, the exponential data volume and diversity growth, characteristic of prevalent extensive data systems, pose challenges. Without adequate data management, these environments become unwieldy and labyrinthine, complicating operations.
“The shift from centralized to distributed working
requires organizations to make data, and data management capabilities,
available more rapidly and in more places than ever before.” – Gartner
Data management has remained a cornerstone practice embraced by various industries for decades, although with varying interpretations and applications. Within Databricks, the perception of data management transcends mere organizational processes; it encompasses a comprehensive approach to harnessing data as a pivotal strategic asset. This holistic view entails data management’s collection, processing, governance, sharing, and analytical aspects, all orchestrated to operate seamlessly, ensuring cost-efficiency, effectiveness, and unwavering reliability.
The uninterrupted data flow across individuals, teams, and operational segments is a linchpin for organizational resilience and innovation. Many enterprises struggle with effectively harnessing and capitalizing on their data assets despite the growing recognition of data’s value. Irrespective of whether it is in steering product decisions through data-driven insights, fostering collaboration, or venturing into new market channels.
Forrester’s insights underscore a staggering reality: an estimated 73% of company data remains untapped, languishing without utilization in analytics and decision-making. This untapped potential significantly impedes businesses striving for success in today’s data-driven economy.
The predominant flow of company data converges into expansive data lakes, serving as the nucleus for data preparation and validation. However, while these lakes cater to downstream data science and machine learning endeavors, a parallel influx of data is rerouted to various data warehouses specifically designed for business intelligence. The necessity for this bifurcation arises from the inadequacies of traditional data lakes, which often prove sluggish and unreliable for BI workloads. Complicating matters further is the dynamics of data management, which require periodic migration between data lakes and warehouses. Additionally, the emergent landscape of machine learning workloads further complicates this ecosystem as these processes increasingly interact with data lakes and warehouses. The crux of the challenge lies in the inherent disparities between these foundational elements of data management.
Critical Concerns in Data Management
- Lack of Data Insight: The accumulation of data from diverse sources, spanning smart devices, sensors, video feeds, and social media, remains futile without robust implementation strategies. Organizations must scale infrastructure adequately to harness this data reservoir effectively.
- Difficulty in Maintaining Performance Level: Amplified data collection leads to a denser database, demanding continuous index modifications to sustain optimal response times. This pursuit of peak performance across the organization poses a challenge, requiring meticulous query analysis and index alterations.
- Challenges Regarding Changing Data Requirements: Evolving data compliance mandates present a complex landscape, demanding continuous scrutiny to align data practices with dynamic regulations. Monitoring personally identifiable information (PII) is pivotal, ensuring strict adherence to global privacy requirements.
- Difficulty Processing and Converting Data: Efficient data utilization hinges on prompt processing and conversion. Delays in these operations render data obsolete, impeding comprehensive data analysis and insights crucial for organizational decision-making.
- Difficulty in Effective Data Storage: Data storage in lakes or warehouses demands adaptability to diverse formats. Data scientists face time constraints while transforming data into structured formats suitable for storage, which is crucial for rendering data analytically useful across various models and configurations.
- Difficulty in Optimizing IT Agility and Costs: As businesses transition from offline to online systems, diverse storage options—cloud-based, on-premises, or hybrid—emerge. Optimizing data placement and storage methods becomes pivotal for the IT sector, ensuring maximum agility while minimizing operational costs. Efficient decision-making in data storage locations becomes imperative for cost-effective and agile IT operations.
 Data Ingestion
Data Ingestion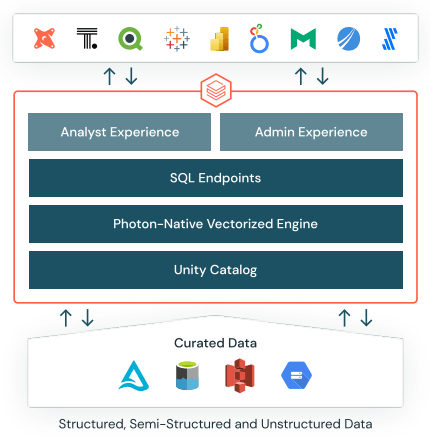 Databricks SQL augments existing BI tools by providing a SQL-native interface, enabling direct querying of data lake contents within the Databricks platform. A dedicated SQL workspace within the system facilitates an environment familiar to data analysts, empowering them to execute ad hoc queries, generate insightful visualizations, and compile these visualizations into intuitive, drag-and-drop dashboards. These dashboards are readily shareable across stakeholders within the organization.
Databricks SQL augments existing BI tools by providing a SQL-native interface, enabling direct querying of data lake contents within the Databricks platform. A dedicated SQL workspace within the system facilitates an environment familiar to data analysts, empowering them to execute ad hoc queries, generate insightful visualizations, and compile these visualizations into intuitive, drag-and-drop dashboards. These dashboards are readily shareable across stakeholders within the organization.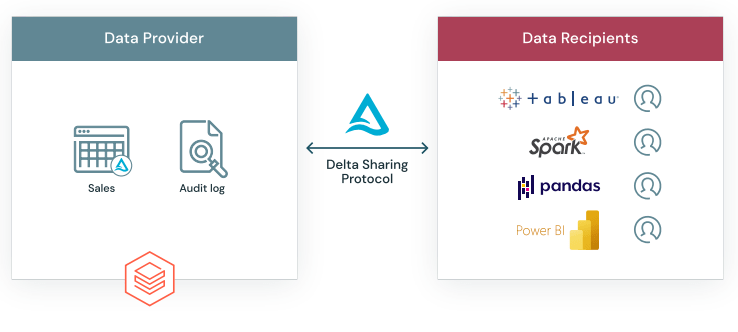 The protocol prioritizes privacy and compliance, ensuring robust security and privacy controls for administrators. These controls encompass access authorization, tracking, and auditing of shared data; all managed from a centralized enforcement point.
The protocol prioritizes privacy and compliance, ensuring robust security and privacy controls for administrators. These controls encompass access authorization, tracking, and auditing of shared data; all managed from a centralized enforcement point.